并发 Concurrence
Concurrence
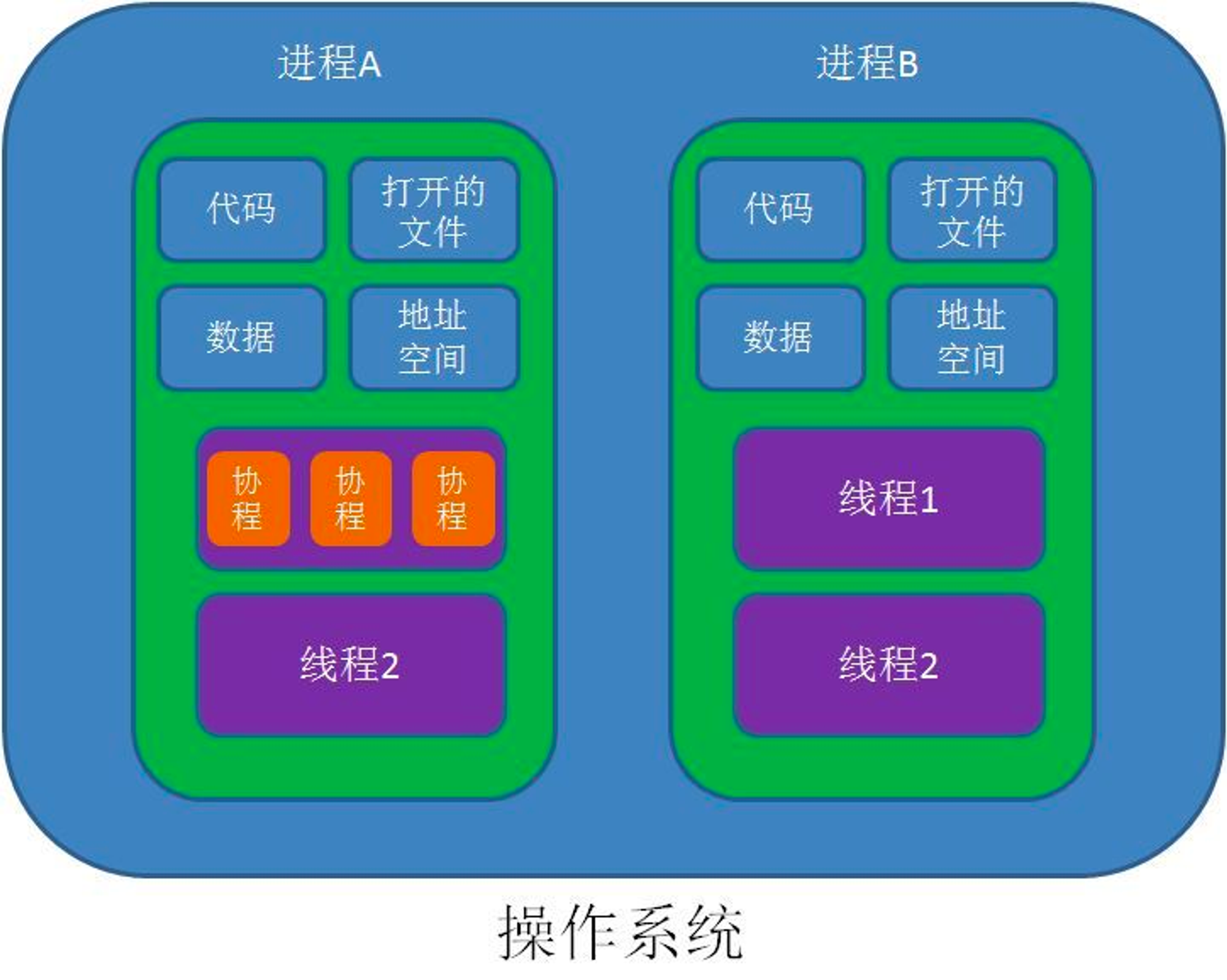
Java 进程、线程、协程
Java 进程、线程和协程是多任务编程中的重要概念,它们之间的区别如下:
✅ 进程(Process):是操作系统资源分配和调度的基本单位。进程拥有独立的地址空间、文件描述符、堆栈等资源,进程之间相互独立。在 Java 中,可以通过 ProcessBuilder 或 Runtime.exec() 创建和管理进程。
✅ 线程(Thread):是操作系统调度的最小单位。线程是在进程内部创建和管理的,它共享进程的资源,包括地址空间、文件描述符、堆栈等,但拥有独立的程序计数器和栈空间。在 Java 中,可以通过 Thread 类来创建和管理线程。
✅ 协程(Coroutine):是一种用户级别的轻量级线程,也称为协作式多任务处理。协程通过用户代码调度,不需要操作系统介入,因此比线程更轻量级,开销更小。在 Java 中,可以使用一些第三方库来实现协程,如 Quasar、Kotlin 协程等。
总体来说,进程和线程是操作系统级别的概念,而协程是更高级别的用户级别概念。进程和线程具有明显的层次性和隔离性,但开销较大;协程具有轻量级和高效的特点,但需要编写更多的代码来实现调度和同步。
需要注意的是,在 Java 中,线程是非常重要的概念,Java 应用程序往往会使用大量的线程来处理并发和并行任务。协程在 Java 中并不是原生支持的概念,需要借助第三方库来实现。
一个进程可以包含多个线程,线程之间共享进程的资源和内存空间。线程可以使用同步机制来避免数据竞争和死锁等问题。在一个线程内部,可以使用协程来实现异步任务和 IO 操作等场景,从而提高并发执行的效率。
线程的生命周期、及状态
线程的 5 种状态: 创建、就绪、运行、阻塞、死亡。
阻塞的 3 种情况:
| 阻塞类型 | 描述 |
|---|---|
| 等待阻塞 | 运行的线程执行 wait 方法,该线程会释放占用的所有资源,JVM 会将该线程放入 “等待池” 中。进入这个状态之后,是不能自动唤醒的,必须依靠其他线程调用 notify 或 notifyAll 方法才能被唤醒。wait 是 Object 类的方法。 |
| 同步阻塞 | 运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则 JVM 会将该线程放入 “锁池” 中。 |
| 其他阻塞 | 运行的线程执行 sleep 或 join 方法,或者发出了 I/O 请求 时,JVM 会将该线程置为阻塞状态。当 sleep 状态超时、join 等待线程终止或超时、I/O 处理完毕时,线程重新转入就绪状态。 sleep 是 Thread 类的方法。 |
| 状态 | 描述 |
|---|---|
| 新建状态(New) | 新创建了一个线程对象。 |
| 就绪状态(Runnable) | 线程对象创建后,其他线程调用了该对象的 start 方法。该状态的线程位于 可运行线程池 中,变得可运行,等待获得 CPU 的使用权。 |
| 运行状态(Running) | 就绪状态的线程获取了 CPU,执行程序代码。 |
| 阻塞状态(Blocked) | 阻塞状态是线程因为某种原因放弃 CPU 使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。 |
| 死亡状态(Dead) | 线程执行完了或者因异常退出了 run 方法,该线程结束生命周期。 |
线程的生命周期 通常包括五种状态:新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)和终止(Terminated)。其中:
▪ 在线程的生命周期中,线程状态的转换通常是由操作系统调度和控制的。
▪ 当线程的状态发生变化时,需要进行上下文切换,即保存当前线程的状态和上下文信息,并恢复另一个线程的状态和上下文信息,使其能够继续执行。
▪ 上下文切换会带来一定的开销,因此需要尽可能减少线程之间的切换次数。
✅ 线程上下文切换
CPU通过分配时间片来执行任务,当一个任务的时间片用完,就会切换到另一个任务。在切换之前会保存上一个任务的状态,当下次再切换到该任务,就会加载这个状态。
线程的生命周期通常包括五种状态:新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)和终止(Terminated)。
| 状态 | 描述 |
|---|---|
| New (新建状态) | 线程正在被创建时的状态(已分配相应的内存空间、资源等,但还没开始运行) |
| Runnable(就绪状态) | 线程创建完成以后,具备运行条件,但由于没有空闲 CPU 暂时无法运行。 此时线程位于可运行线程池中,等待获取 CPU 的使用权。 (当线程对象调用 start( ) 之后) |
| Running(运行状态) | 线程在 CPU 上运行时的状态 |
| Blocked(阻塞状态) | 线程在某些特定情况下,会被挂起,暂时停止运行。(线程处于阻塞状态,它不会占用 CPU 资源) |
| Terminated(终止状态) | 线程结束生命周期(释放资源,彻底消失) |
并发编程三要素
并发三大特性
并发、并行、串行
| 含义 | 场景 | |
|---|---|---|
| 并发 (Concurrency) | 多个任务同一时间间隔发送 宏观上同时发送,微观上交替进行 系统中同时存在多个正在执行的任务,并且这些任务可能会相互影响。 并发通常用来处理多个任务共享资源的情况。 | 在单核 CPU 中,时间片轮转 |
| 并行 (Parallelism) | 真正意义上的同时处理多个任务 系统中同时存在多个并且相互独立的任务,并且这些任务可以在多个处理器上同时执行。 | 多个处理器处理多个独立的任务 |
| 同步 (Synchronous) | 为完成某种任务,程序需要在某些位置上协调它们的工作次序而产生的制约关系,又称直接制约关系。 程序按照代码的顺序执行,一行一行的执行,直到当前执行完成后才能继续执行下一行。 同步会阻塞调用者,直到任务完成才能返回。 | 进程同步 |
| 异步 (Asynchronous) | 程序执行某个任务时,不需要等待该任务完成,可以直接进行下一个任务,等任务完成后再进行相应处理,提高系统并发性能。 异步通常不会阻塞调用者。 | 并发计算 并发编程 |
并发和并行针对的是任务的执行方式;
同步和异步针对的是任务执行的阻塞和返回方式。
串行:在时间上不可能发生重叠,前一个任务没搞定,下一个任务就只能等着
并发:在时间上是重叠的,两个任务在同一时刻互不干扰的同时执行
并发:允许两个任务彼此干扰。同一时间点,只有一个任务运行,交替执行。
Java 如何开启线程以及保证线程安全?
线程和进程的区别:
进程是操作系统进行资源分配的最小单元。
线程是操作系统进行任务分配的最小单元,线程隶属于进程。
如何开启线程?
1、继承 Thread 类,重写 run()。
2、实现 Runnable 接口,实现 run()。
3、实现 Callable 接口,实现 call()。通过 FutureTask 创建一个线程,获取到线程执行的返回值。
4、通过线程池来开启线程。
怎么保证线程安全?
核心思想:加锁
1、 JVM 提供的锁,也就是 Synchronized 关键字。
2、 JDK 提供的各种锁 Lock(基础 Lock 接口实现的各种锁)。
线程安全
不是线程安全,应该是内存安全,堆是共享内存,可以被所有线程访问。
定义
当多个线程访问一个对象时,如果不用进行额外的同步控制或其他的协调操作,调用这个对象的行为都可以获得正确的结果,我们就说这个对象是线程安全的。
堆
堆是进程和线程共有的空间,分全局堆、局部堆。
- 全局堆:所有没有分配的空间。
- 局部堆:用户分配的空间。
堆在操作系统对进程初始化的时候分配,运行过程中也可以向系统要额外的堆,但是用完了要还给操作系统,要不然就是内存泄漏。
在 Java 中,堆是 Java 虚拟机管理的内存中最大的一块,是所有线程共享的一块内存区域,在虚拟机启动时创建。 堆所存在的内存区域的唯一目的就是 存放对象实例,几乎所有的对象实例以及数组都在这里分配内存。
栈
- 栈是每个线程独有的,保存其运行状态和局部变量。
- 栈在线程开始的时候初始化,每个线程的栈相互独立。因此,栈是线程安全的。
- 操作系统在切换线程的时候会自动切换栈。
- 栈空间不需要在高级语言里,显式的分配和释放。
CountDownLatch 和 Semaphore 区别,及其底层原理。
CountDownLatch 表示计数器,可以给 CountDownLatch 设置一个数字,一个线程调用 COuntDownLatch 的 await() 将会阻塞,其他线程可以调用 CountDownLatch 的 countDown() 方法来对 CountDownLatch 中的数字 -1,当数字 == 0 时,所有 await 的线程都将被唤醒。
CountDownLatch 底层原理:
调用 await() 方法的线程,会利用 AQS 排队,一旦数字减为 0,则会将 AQS 中排队的线程依次唤醒。
Semaphore 表示信号量,可以设置许可的个数,表示同时允许最多多少个线程使用该信号量,通过 acquire() 来获取许可,如果没有许可可用则线程阻塞,并通过 AQS 来排队,可以通过 release() 来释放许可,当某个线程释放了某个许可后,会从 AQS 中正在排队的第一个线程开始依次唤醒,直到没有空闲许可。
public class CountDownLatchTest {
static CountDownLatch countDownLatch = new CountDownLatch(3);
public static void main(String[] args) throws InterruptedException {
// 线程1
countDownLatch.await();
// 线程5, 再次调用 await() 会解除线程1 的阻塞【方式2:解除阻塞】
countDownLatch.await();
// 线程2
countDownLatch.countDown();
// 线程3
countDownLatch.countDown();
// 线程4, 执行 3 次 countDown() 方法,就是解除线程1 的阻塞【方式1:解除阻塞】
countDownLatch.countDown();
}
}
public class SemaphoreTest {
// 3个信号量许可
static Semaphore semaphore = new Semaphore(3);
public static void main(String[] args) throws InterruptedException {
// 线程1
semaphore.acquire();
// 线程2
semaphore.acquire();
// 线程3
semaphore.acquire();
// 线程4, 没有信号量许可了 → 阻塞
semaphore.acquire();
// 线程1, 释放许可 → AQS 中的线程4 会被唤醒
semaphore.release();
}
}
ReentrantLock 中 tryLock() 、lock()
tryLock()
- 尝试加锁,可能加到,也可能加不到。
- 不会阻塞线程
- 返回值:加到锁,返回 true;没有加到锁,返回 false。
lock()
- 阻塞加锁。
- 线程会阻塞,直到加到锁。
- 返回值:无
public class ReentrantLockTest {
//
static ReentrantLock reentranLock = new ReentrantLock(3);
public static void main(String[] args) throws InterruptedException {
// 阻塞加锁
reentranLock.lock();
// 其他代码不会执行,释放锁之后才会执行
// 尝试加锁,非阻塞
boolean result = reeentranLock.tryLock();
// 自旋锁,消耗 CPU 多,更加灵活
while (!reentranLock.tryLock()) {
// 其他事情【尝试加锁,加到锁之后才会执行】
}
// 其他代码
}
}
ReentrantLock 中公平锁、非公平锁
公平锁、非公平锁的底层实现,都会使用 AQS 来进行排队。【默认是非公平锁,因为其性能高】
区别:
线程在使用 lock() 加锁时,
如果是公平锁,会先检查 AQS 队列中是否存在线程在排队,如果有线程在排队,则当前线程也进行排队;如果是非公平锁,则不会检查是否有现成在排队,而是直接竞争锁。
公平锁/非公平锁,一旦没竞争到锁,都会进行排队。当锁释放时,都是唤醒排在最前面的线程,所以非公平锁只是体现在了 线程加锁阶段,而没有体现在唤醒阶段。
ReentrantLock 是可重入锁。【公平锁、非公平锁都是可重入锁】
public class ReentrantLockTest {
static ReentrantLock reentranLock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
// 阻塞加锁
reentranLock.lock();
reentranLock.lock();
// 解锁,由于加锁 2次,故要解锁 2次
reentranLock.unlock();
reentranLock.unlock();
}
}
sleep()、wait()、join()、yield()
锁池
所有需要 竞争同步锁的线程 都会放在锁池当中, 比如当前对象的锁已经被其中一个线程得到,则其他线程需要在这个锁池进行等待; 当前面的线程释放同步锁后,锁池中的线程去竞争同步锁,当某个线程得到后会进入就绪队列进行等待 CPU 资源分配。
等待池
当我们调用 wait() 方法后,线程会放到等待池中,等待池的线程不会去竞争同步锁。 只有调用了 notify() 或 notifyAll() 后等待池的线程才会开始去竞争同步锁。 notify() 是随机从等待池选出一个线程放到锁池,而 notifyAll() 是将等待池的所有线程放到锁池中。
sleep() 和 wait()
sleep()是 Thread 类的静态本地方法;wait()是 Object 类的本地方法。sleep()不会释放lock;wait()会释放lock,并加入到等待队列中。sleep()不依赖同步器synchronized;wait()需要依赖synchronized关键字。sleep()不需要被唤醒(休眠之后退出阻塞);wait()需要被唤醒(不指定时间需要被别人中断)。sleep()一般用于当前线程休眠,或者轮询暂停操作;wait()则多用于多线程直接的通信。sleep()会让出 CPU 执行时间且强制上下文切换;wait()则不一定,wait 后可能还是有机会重新竞争到锁继续执行的。
yield()
yield() 执行后线程进入就绪状态,马上释放了 CPU 的执行权,但是依然保留了 CPU 的执行资格, 所以有可能 CPU 下次进行线程调度时,还会让这个线程获取到执行权继续执行。
join()
join() 执行后线程进入阻塞状态。例如,在线程 B 中调用线程 A 的 join(),则线程 B 会进入到阻塞队列,直到线程 A 结束或中断。
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("222222");
}
});
t1.start();
t1.join();
// 这行代码必须要等 t1 全部执行完毕,才会执行
System.out.println("111");
}
// 执行结果
222222
111
1. 锁池
所有需要竞争同步锁的线程都会放到锁池中。
比如当前对象中的锁已经被其中一个线程得到,则其他线程需要在这个锁池中进行等待,当前面的线程释放同步锁后,锁池中的线程去竞争同步锁,当某个线程得到锁后,就会进行就绪队列进行等待 CPU 资源分配。
2. 等待池
调用 wait() 后,线程会放到等待池中。
等待池的线程不会去竞争同步锁。只有调用了 notify() 或 notifyAll() 后,等待池的线程才会开始去竞争锁。
notify() 是随机从等待池中选出一个线程放到锁池。
notifyAll() 是将等待池的所有线程放到锁池。
sleep() 是 Thread 类的静态本地方法。
不会释放 lock。
不依赖于同步器 Sychronized。
不需要被唤醒(休眠之后退出阻塞)
一般用于当前线程休眠,或者轮询暂停操作
会让出 CPU 执行时间且强制上下文切换
wait() 是 Object 类的本地方法。
会释放 lock,并且将线程加入到等待队列。
依赖于同步器 Sychronized
需要被唤醒(不指定时间,需要被别人中断)
多用于多线程之间的通信
不一定让出 CPU,wait() 后可能还是有机会重新竞争到锁继续执行
yield() 执行后,线程直接进入就绪状态,马上释放了 CPU 的执行权,但是依然保留了 CPU 的执行资格,所以有可能 CPU 下次进行线程调用还会让这个线程获取到执行权继续执行。
join() 执行后,线程进入阻塞状态。
例如,在线程 B 中调用线程 A.join(), 则线程 B 会进入到阻塞状态,直到线程 A 结束或中断。
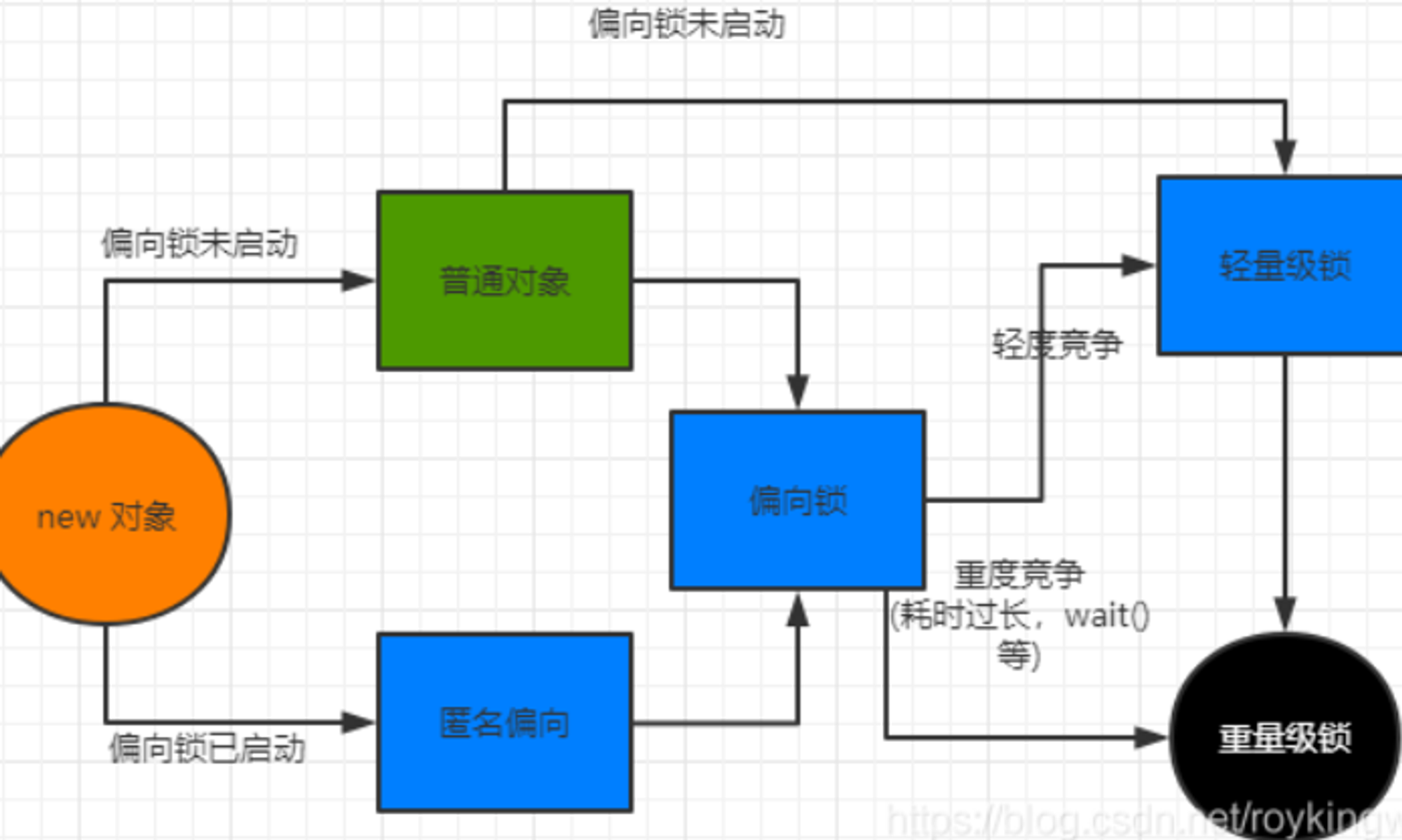
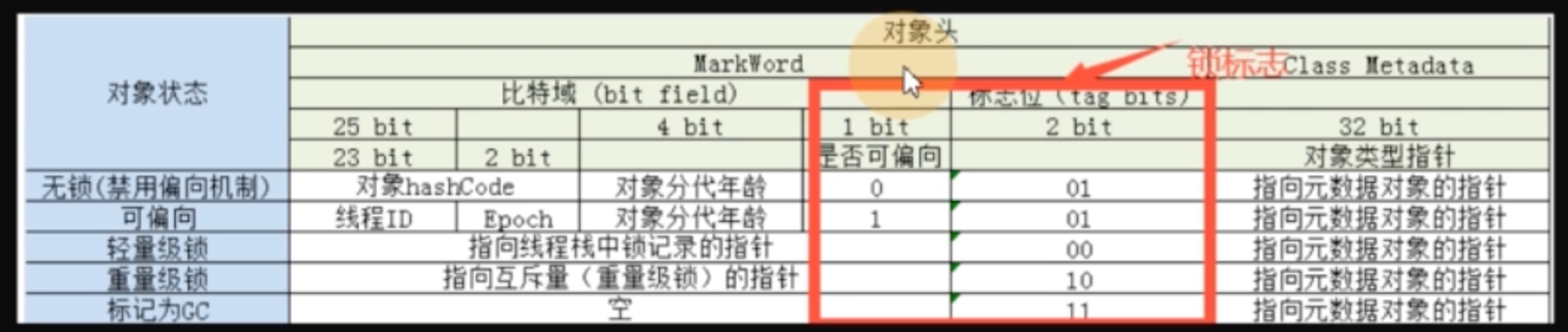
Sychronized 的偏向锁、轻量级锁、重量级锁
自旋锁
自旋锁在线程获取锁的过程中,不会去阻塞线程,也就无所谓唤醒线程【阻塞和唤醒线程都是需要操作系统去进行的,比较消耗时间】。
自旋锁是线程通过 CAS 获取预期的一个标记,如果没有获取到锁,则继续循环执行,直到获取到锁为止。
这个过程,线程一直在运行中,相对而言没有使用太多的操作系统资源,比较轻量。
偏向锁
在锁对象的对象头中记录一下当前获取到 该锁的线程 id,该线程下次如果又来获取锁就可以直接获取到!
轻量级锁
由偏向锁升级而来,当一个线程获取到锁后,此时这把锁是偏向锁。
此时,如果有第二个线程来竞争锁,偏向锁就会升级为轻量级锁。
此处,之所以称之为轻量级锁,是为了与重量级锁区分。轻量级锁底层是通过自旋来实现的,并不会阻塞线程
重量级锁
如果自旋次数过多,仍然没有获取到锁,则会升级为重量级锁。
重量级锁会导致线程阻塞。
Sychronized 和 ReentrantLock 区别
| sychronized | ReentranLock |
|---|---|
| 是一个关键字 | 是一个类 |
| 会自动加锁/释放锁 | 需要手动加锁/释放锁 |
| 底层是 JVM 层面的锁 | API 层面的锁 |
| 非公平锁 | 公平锁/非公平锁【可选】 |
| 锁的是对象,锁信息保存在对象头中 | 通过代码中 int 类型的 state 标识,来标识锁的状态 |
| 底层有一个锁升级的过程 |
Thread 和 Runnable
问出该问题的面试官,水平一般。本质是没什么区别的。
Thread 和 Runnable 的实质是继承关系,没有可比性。
无论使用 Thread 还是 Runnable,都会 new Thread,然后执行 run()。
用法上,如果有复杂的线程操作需求,就选择继承 Thread;如果只是简单的执行一个任务,则实现 Runnable。
// 会多出一倍的票
// 共享资源,该观点是错误的 ❌
public class Test {
public static void main(String[] args) {
new MyThread().start();
new MyThread().start();
}
static class MyThread extends Thread {
private int ticket = 5;
public void run() {
while (true) {
System.out.println("Thread ticket = " + ticket--);
if (ticket < 0) {
break;
}
}
}
}
}
// 正常卖出
public class Test2 {
public static void main(String[] args) {
MyThread2 mt = new MyThread2();
new Thread(mt).start();
new Thread(mt).start();
}
static class MyThread2 implements Runnable {
private int ticket = 5;
public void run() {
while (true) {
System.out.println("Runnable ticket = " + ticket--);
if (ticket < 0) {
break;
}
}
}
}
}
原因:MyTread 创建了 2 个实例,So 自然会卖出两倍,属于用法错误。
实际上,应该将 ticket 定义为 private static,并且加同步锁 Sychronized
run()、start()
start 开启新的线程
run 和 普通 Java 方法没有区别
ThreadLocal 底层原理
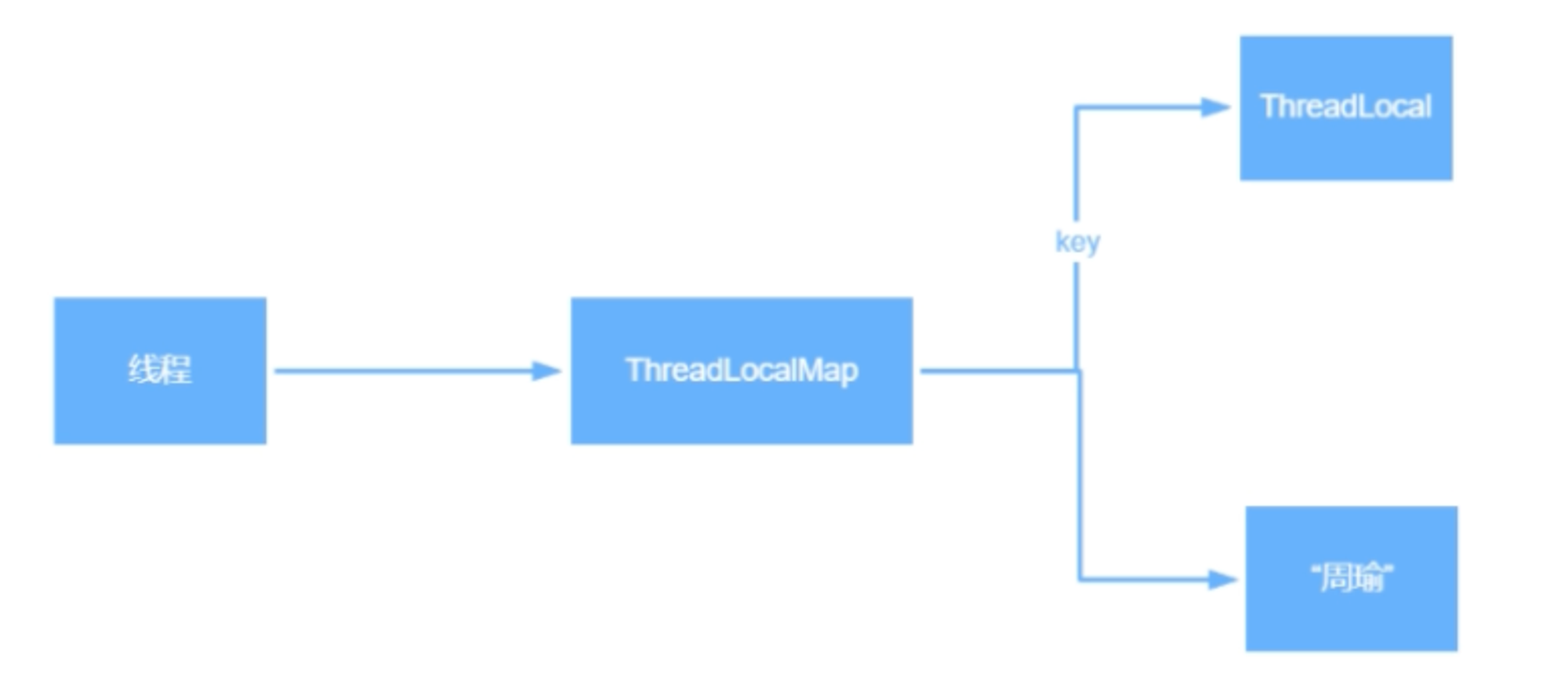
1. ThreadLocal 是 Java 所提供的线程本地存储机制,可以利用该机制将数据缓存在某个线程内部,该线程可以在任意时刻、任意方法中获取缓存的数据。
2. ThreadLocal 底层是通过 ThreadLocalMap 来实现的,每个 Thread 对象(注意不是 ThreadLocal 对象)中都存在一个 ThreadLocalMap,Map 的 key 为 ThreadLocal 对象,Map 的value 为需要缓存的值。
3. 如果在线程池中使用 ThreadLocal 会造成内存泄露,因为当 ThreadLocal 对象使用完之后,应该要把设置的 key、value,也就是 Entry 对象进行回收,但线程池中的线程不会回收,而线程对象是通过强引用指向 ThreadLocalMap,ThreadLocalMap 也是通过强引用指向 Entry 对象,线程不会被回收,Entry 对象也就不会被回收,从而出现内存泄露。
解决方法:
在使用了 ThreadLocal 对象之后,手动调用 ThreadLocal 的 remove(),手动清除 Entry 对象。
4. ThreadLocal 经典的应用场景:连接管理(一个线程持有一个连接,该连接对象可以在不同的方法之间进行传递,线程之间不共享同一个连接)
public class ThreadLocalTest {
private static ThreadLocal<String> s = new ThreadLocal<>();
public static void main(String[] args) {
s.set("siona");
String s1 = ThreadLocalTest.s.get();
// 手动清除 Entry 对象
s.remove();
}
}
ThreadLocal 内存泄露问题,如何避免?
内存泄露为程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果严重,无论多少内存,迟早会被占光。
不再会被使用的对象或者变量占用的内存不能被回收,就是内存泄露。
OOM:内存已经不足!!!
强引用:
使用最普遍的引用(new),一个对象具有强引用,不会被垃圾回收器回收。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不回收这种对象。
弱引用:
JVM 进行垃圾回收时,无论内存是否充足,都会回收被弱引用关联的对象。
在 Java 中,用 java.lang.ref.WeakReference 类来表示。
可以在缓存中使用弱引用。
ThreadLocal 实现原理,每一个 Thread 维护一个 ThreadLocalMap,key 为使用弱引用的 ThreadLocal 实例,value 为线程变量的副本。

ThreadLocalMap 使用 ThreadLocal 的弱引用作为 key,如果一个 ThreadLocal 不存在外部强引用时,key(ThreadLocal) 势必会被 GC 回收,这样就导致 ThreadLocalMap 中 key 为 null,而 value 还存在着强引用,只有 Thread 线程退出之后,value 的强引用链条才会断掉,但如果当前线程再迟迟不结束的话,这些 key 为 null 的 Entry 的 value 就会一直存在一条强引用链(红色链条)
key 使用强引用:
当 ThreadLocalMap 的 key 为强引用,回收 ThreadLocal 时,因为 ThreadLocalMap 还持有 ThreadLocal 的强引用,如果没有手动删除,ThreadLocal 不会被回收,导致 Entry 内存泄露。
key 使用弱引用:
当 ThreadLocalMap 的 key 为弱引用,回收 ThreadLocal 时,由于 ThreadLocalMap 持有 ThreadLocal 的弱引用,即使没有手动删除,ThreadLocal 也会被回收。
当 key 为 null,在下一次 ThreadLocalMap 调用 set()、get()、remove() 时,value 值会被清除。
因此,ThreadLocal 内存泄露的根源:
由于 ThreadLocalMap 的生命周期与 Thread 一样长,如果没有手动删除对应 key,就会导致内存泄露,而不是因为弱引用。
ThreadLocal 正确的使用方法:
1. 每次使用完 ThreadLocal 后,都调用它的 remove() 清楚数据。
2. 将 ThreadLocal 变量定义成 private static,这样就一直存在 ThreadLocal 的强引用,也就能保证任何时候都能通过 ThreadLocal 的弱引用访问到 Entry 的 value 值,进而清除掉。
ThreadLocal 父子线程共享数据
Volatile 和 Sychronized 区别。Volatile 能否保证线程安全?DCL 单例为何要加 Volatile?
1、Synchronized 关键字,用来加锁。
Volatile 只是保持变量的线程可见性。通常适用于一个线程写,多个线程读的场景。
2、不能。Volatile 关键字只能保证线程可见性,不能保证原子性。
3、Volatile 防止指令重排。在 DCL 中,防止高并发情况下,指令重排造成的线程安全问题。
public class VolatileDemo {
public static /*volatile*/ boolean flag = true;
public static void main(String[] args) {
new Thread(() -> {
while (flag) {
}
System.out.println("====== End of Thread1 ======");
}).start();
try {
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("true flag off");
flag = false;
}
}
# 不加 Volatile 关键字,输出以下结果
# 分析:主线程执行完,并设置 flag = true
# 但线程1 一直在 while 循环,即 flag = true,并未感知到 flag = false
true flag off
# 加上 volatile 关键字之后,输出以下结果
# 分析:线程1 感知到 flag = false,执行结束。
true flag off
====== End of Thread1 ======
public class SingleDemo {
private static SingleDemo singleDemo = new SingleDemo();
private SingleDemo() {}
// 多个线程创建时,线程不安全 → 加锁
// 方法 1. 加在方法上,锁粒度太大
// 方法 2. 方法内加锁
public static /*sychronized*/ SingleDemo getInstance () {
if (null == singleDemo) {
/* 2. 后进来的线程会卡在这里,依然线程不安全
sychronized(SingleDemo.class) {
singleDemo = new SingleDemo();
}
*/
sychronized(SingleDemo.class) {
// 检查,加锁之后,再检查一次,就是 DCL (Double Check Lock) 单例
if (null == SingleDemo) {
singleDemo = new SingleDemo();
}
}
}
return singleDemo;
}
}
Volatile 关键字,如何保证可见性、有序性?
指令重排序
“内存可见性” 问题
主内存、工作内存
Java 线程锁机制,锁升级过程。
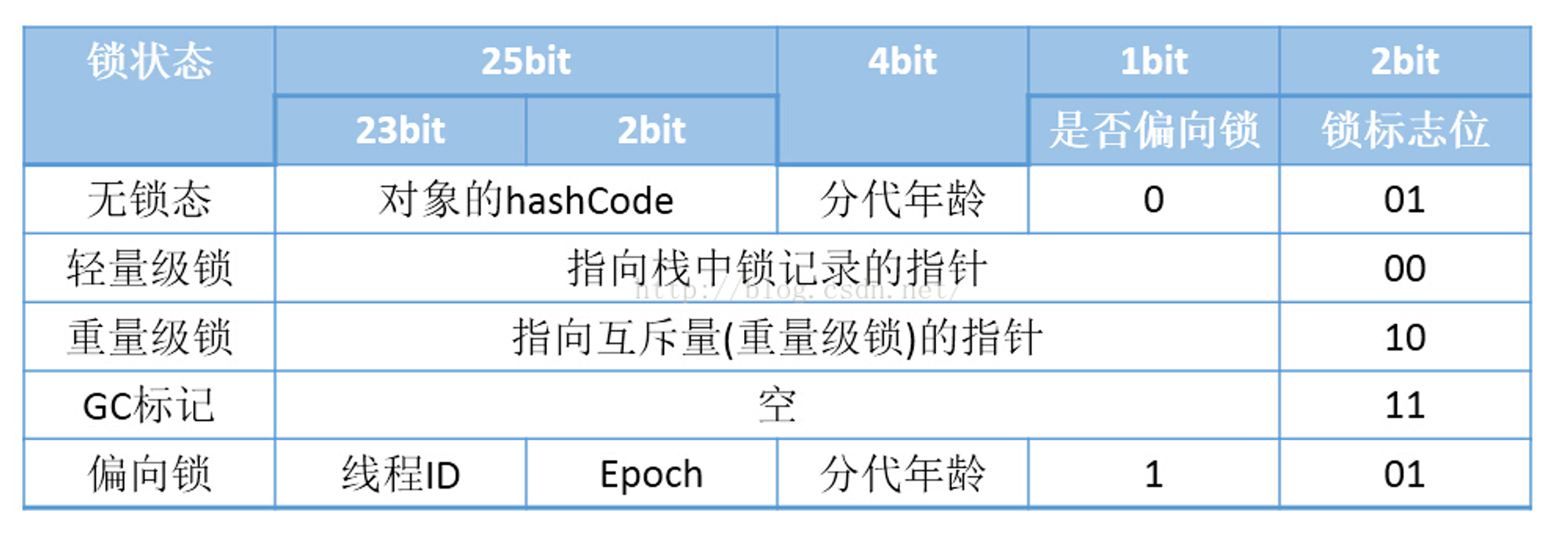
1、JAVA 的锁就是在对象的 Markword 中记录一个锁状态。
无锁,偏向锁,轻量级锁,重量级锁对应不同的锁状态。
2、JAVA 的锁机制就是根据资源竞争的激烈程度不断进行锁升级的过程。
/**
* 打印对象在内存中的布局
*/
public class JOLTest {
public static void main(String[] args) {
Object o = new Object();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
sychronized(o) {
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
}
<!-- pom.xml 文件 -->
<!-- 作用:对象在内存中布局 -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.10</version>
</dependency>
AQS,AQS 如何实现可重入锁?
1、AQS 是一个 JAVA 线程同步的框架。是 JDK 中很多锁工具的核心实现框架。
2、在 AQS 中,维护了一个信号量 state 和一个线程组成的双向链表队列。
其中,这个线程队列,就是用来给线程排队的,而 state 就像是一个红绿灯,用来控制线程排队或者放行的。
在不同的场景下,有不用的意义。
3、在可重入锁这个场景下,state 就用来表示加锁的次数。
0 标识无锁,每加一次锁,state就 +1。释放锁 state 就 -1。
如何避免 Java 死锁?
死锁问题的解决策略
如何查看线程死锁?
1. 通过 jstack 命令进行查看,jstack 命令中会显示发生了死锁的线程
2. 两个线程去操作数据库时,导致数据库发生了死锁。
此时,可以查询数据库的死锁情况。
1. 查询是否锁表
show OPEN TABLES where In_use > 0;
2. 查询进程
show processlist;
3. 查看正在锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
4. 查看等待锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
线程之间如何进行通信?
1. 线程之间可以通过共享内存 / 基于网络 来进行通信
2. 如果是通过共享内存来进行通信,则需要考虑并发问题,什么时候阻塞,什么时候唤醒
3. 像 Java 中的 wait()、notify() 就是阻塞和唤醒
4. 通过网络就比较简单了,通过网络连接将通信数据发送给对方,当然也要考虑到并发问题,处理方式就是加锁等方式
如何保证多个线程之间的执行顺序?同时、依次、有序交错执行
CountDownLatch, CylicBarrier, Semaphore。
如何对一个字符串快速进行排序?
Fork/Join框架
守护线程
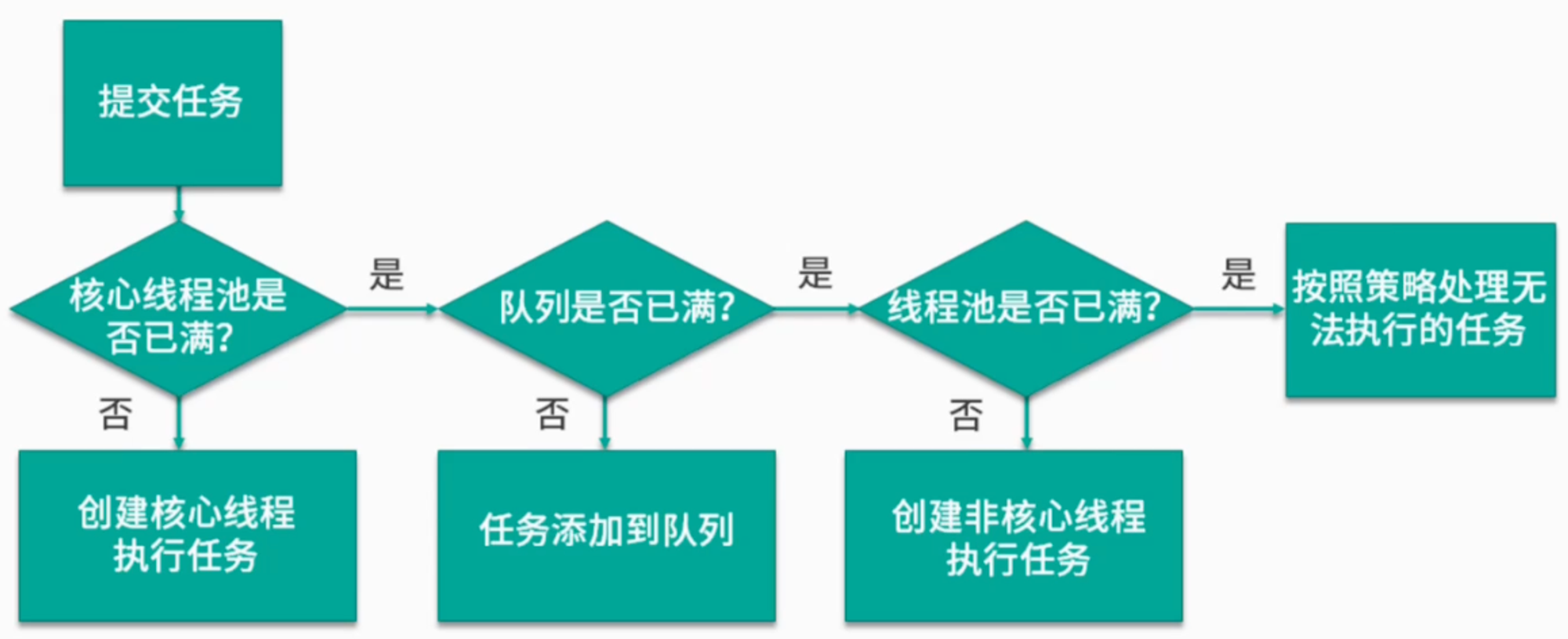
线程池及其参数解释
package com.siona.study;
import java.util.concurrent.*;
/**
* 定制线程池
*
* @Description TODO
* @Version 1.0.0
* @Date 2024/01/05 13:35
* @Created by Siona
*/
public class ThreadStudy {
public static void main(String[] args) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(1);
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
ExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
ExecutorService singleThreadScheduleExecutor = Executors.newSingleThreadScheduledExecutor();
/**
* 参数信息:
* int corePoolSize 核心线程大小
* int maximumPoolSize 线程池最大容量大小
* long keepAliveTime 线程空闲时,线程存活的时间
* TimeUnit unit 时间单位
* ArrayBlockingQueue<Runnable> workQueue 任务队列
* threadFactory 线程工厂
* handler 执行拒绝策略的对象
*/
ThreadPoolExecutor executor = new ThreadPoolExecutor(
1,
1,
0L,
TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<>(1),
new CustomThreadFactory(),
new CustomThreadRejectionHandler()
);
executor.execute(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 测试:每 5 秒去抛出一个错误
throw new RuntimeException("我报错了~");
});
executor.execute(() -> {
System.out.println("-");
});
executor.execute(() -> {
System.out.println("这是一个超过队列大小的任务");
});
executor.shutdown();
}
/**
* 自定义线程工厂
*/
static class CustomThreadFactory implements ThreadFactory {
@Override
public Thread newThread(Runnable runnable) {
Thread thread = new Thread(runnable);
thread.setName("自定义线程工厂");
// 异常自定义处理
thread.setUncaughtExceptionHandler((t, e) -> {
System.out.println(t.getName() + "::::::" + e.getMessage());
});
return thread;
}
}
/**
* 自定义线程拒绝策略
*/
static class CustomThreadRejectionHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable runnable, ThreadPoolExecutor threadPoolExecutor) {
// 打印日志、暂存任务、重新执行等拒绝策略
System.out.println("这个任务被拒绝了~");
}
}
}

核心线程大小:根据业务类型和 CPU 核心数考虑,如果线程平均工作时间所占比例越高,那么线程数量应该少一些;如果线程平均等待时间比较高,则需要多一些线程;
线程池最大容量大小:最好是根据 CPU 密集型或者 IO 密集型区分开来设计;
线程空闲时间、存活时间:空闲时间达到多少之后线程才会销毁;
线程池的相关参数:核心线程大小、线程池最大容量大小、线程空闲时间及线程存活时间、任务队列、执行拒绝策略
线程池处理流程
线程池底层工作原理
线程池 -> 线程复用原理
// 原来 Thread 去创建线程时,必须去对应一个任务
new Thread(new Runnable() {
@Override
public void run() {
}
}).start();
线程池会使用一个固定线程大小,或者说可变数量的线程执行任务。
实际应用场景中,设置的线程数量远远小于任务数量。
故线程池可以通过 “线程复用”,让同一个线程执行不同的任务。
实现 “线程复用” 原理:线程池可以将线程和任务解耦,线程是线程、任务是任务。
摆脱了,原来通过 Thread 去创建线程时,必须对应一个任务。
- 线程池中,同一个线程可以从 BlockingQueue 阻塞队列中不断读取新任务,
原理:线程池对 Thread 进行封装,每一个线程去执行一个循环任务,在循环任务中,不断检查是否有新任务。如果有新任务,则去调用该任务的 run() 方法。
CAS 同步机制
compare and swap,解决多线程并行情况下使用锁造成性能损耗的一种机制,
CAS 操作包含三个操作数——内存位置(V)、预期原值(A)和新值(B)。
如果内存位置的值与预期原值相匹配,那么处理器会自动将该位置值更新为新值。否则,处理器不做任何操作。
无论哪种情况,它都会在CAS指令之前返回该位置的值。
CAS有效地说明了“我认为位置V应该包含值A;如果包含该值,则将B放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。
优点:
- 避免加锁
- 提高前期的运行效率
CAS 缺点
1. ABA 问题
当前的值是否与我们预期的值是否是一样的,
A → B → A
比较的时候已经是 A 了,CAS 不会去关注是否发生了变化。
改进:加上版本号,A1 → B2 → C3
# 2. 自旋时间过长
轻量级锁:
单次 CAS 不一定能执行成功的,配合循环(死循环)去进行重试,直到线程竞争不激烈的时候才成功。
如果是高并发场景下,CAS 算法效率是不高的。
故,synchronized 会从轻量级锁,升级成重量级锁。
3. 范围不能灵活控制
针对某一个共享变量(int、long、对象)去进行 CAS,
不能针对多个共享变量去执行,因为多个共享变量是相互独立的状态。
不能简单的把原子操作组合到一起,它们不具有原子性。
如果想对多个共享变量同时进行 CAS 操作,需要保证线程安全,Java 提供了解决方案:new 一个新的类,整合刚才的那一组共享变量。
首先什么是CAS,CAS是一个算法,主要包括三个操作数–内存位置V,预期原值A,新值B
分为三个步骤:
1.读取内存中的值
2.将读取的值和预期的值进行比较
3.如果比较的结果符合预期,则写入新值;如果不符合,则什么都不做
那它有什么缺点呢:
1.ABA问题
2.自旋时间过长
3.范围不能灵活控制
ABA问题:使用CAS算法实现乐观锁时会存在这个问题,
简单来说就是内存的V值被两个线程A和B读取到,值都为0,其中线程A将值改为1提交到内存中.然后线程C又将值A改回0,线程B提交发现值还是0,没有变化,所以它也成功提交.解决ABA问题可以使用版本号机制.JDK 1.5 以后的 AtomicStampedReference 类就提供了此种能力.
自旋时间过长:自旋CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,会给CPU带来非常大的执行开销.synchronized的自旋锁就存在这种问题,这是一种忙等,通过短时间的忙等,换取线程在用户态和内核态之间切换的开销。
范围不能灵活控制:从 JDK 1.5开始,提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用AtomicReference类把多个共享变量合并成一个共享变量来操作.