Java 基础
Java 基础
JDK、JRE、JVM
Java 虚拟机变化(JDK1.7 → jdk1.8)
== 和 equals
==
== 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同, 即是否指向同一个对象。比较的是真正意义上的指针操作。
- 比较的是操作符两端的操作数是否是同一个对象
- 两边的操作数必须是同一类型(可以是父子类之间)才能编译通过
- 比较的是地址,如果是具体的阿拉伯数字的比较,值相等则为 true。如,
int a = 10与long b = 10L与double c = 10.0都是相同的(true),因为它们都指向地址为 10 的堆。
equals
equals 比较两个对象的内容是否相等,由于所有的类都是继承自 java.lang.Object 类,所以适用于所有对象。
如果没有对该方法进行覆盖的话,调用的仍然是 Object 类中的方法,而 Object 类中的 equals() 返回的是
==的判断。
总结
- 比较是否相等,全部用
equals()。 - 与常量进行比较时,把常量写在前面,因为使用 Object 的 equals(),Object 可能为 null,报空指针。
"值".equals(obj)或Object.equals("值", name) - 阿里代码规范中,只使用
equals(),阿里插件默认会识别,并可以快速修改,推荐安装阿里插件来排查老代码使用==,替换成equals()
图灵的解释:
==对比的是栈中的值,基本数据类型是变量值,引用类型是堆中内存对象的地址。equalsObject 中默认采用==比较,通常会重写。
// Object.java 类
public boolean equals(Object obj) {
return (this == obj);
}
// String.java 类
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- = 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
上述代码可以看出,String 类中被复写的 equals() 方法其实是比较两个字符串的内容。
hashCode、equals
| 类型 | 返回类型 | 本质 | |
|---|---|---|---|
| hashCode() | Object 类的方法 | int | 返回一个代表对象哈希码的整数值 必须遵循 equals() 被认定为相等的两个对象,必须有相同的哈希码 因为 hashCode 可能会出现 hash 碰撞,所以导致不相等的两个对象 hash 码可能相等 |
| equals() | Object 类的方法 | boolean | 默认通过 == 比较两个对象的内存地址是否相同 ❗️大部分情况下,通过重写equals() 实现自己定义的相等规则 补充:String 类对 equals() 进行了重写 → 比较字符串的值是否相等。 |
| == | 运算符 | boolean | 对于基本类型:比较值是否相等 对于引用类型:比较内存地址是否相等 |
Java 的集合类:
- List
- 有序、可重复
- Set
- 无序、不可重复
使用场景:
Set 中插入元素时,如何判断是否已经存在该元素?
方案1:通过
equals()。但是如果元素太多,该方法就会比较慢。进阶2:有人发明了
哈希算法来提高集合中查找元素的效率。这种方法将集合分成若干个存储区域,每个对象可以计算出一个哈希码,可以将哈希码分组, 每组分别对应某个存储区域,根据一个对象哈希码就可以确定该对象应该存储在哪个区域。
hashCode()理解:它返回的是根据对象的内存地址换算出的一个值。- ① 当集合要添加新的元素时,先调用这个元素的
hashCode(),然后定位到它应该放置的物理位置上。 - ② 如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;
- ③ 如果这个位置上已经有元素了,就调用它的
equals()与新元素进行比较,相同的话就跳过,不相同就散列其它地址。 - 这样,实际调用
equals()的次数大大降低,几乎只需要一两次。
final
✅ 被 final 修饰的变量、方法、类会被当做常量处理
🔹 修饰变量
▪ 修饰基本数据类型: 数据不可变
▪ 修饰引用数据类型: 地址不可变 (内容可变)
🔹 修饰方法: 不可以重写
🔹 修饰类: 不可以继承
✅ ( 选记,理解不了建议不记 ) 在 Java 内存模型中,final 的语义如下:
▪ 构造函数内对⼀个 final 域的写⼊,与随后把这个被构造对象的引⽤赋值给⼀个引⽤变量,这两个操作之间不能重排序。(JVM 禁⽌编译器把 final 域的写重排序到构造函数之外)
▪ 初次读⼀个包含 final 域的对象的引⽤,与随后初次读这个 final 域,这两个操作之间不能重排序
✅ 好处:
▪ 防止它们被改变,安全
▪ 继承时,保持它们的不变性(针对方法和变量)
▪ 可读性好,规范
▪ ( 增加 )final 变量在编译时被转换成常量,这可以提高程序的性能。
- 被 final 修饰的
类,不可以被继承。 - 被 final 修饰的
方法,不可以被重写。 - 被 final 修饰的
变量,不可以被改变。如果修饰引用,则表示引用不可变,引用指向的内容可变。 - 被 final 修饰的方法,JVM 会尝试将其内联,以提高运行效率。
- 被 final 修饰的
常量,在编译阶段会存入常量池中。
String、StringBuffer、StringBuilder
| 可变性(immutable / mutable) | 线程安全 | 应用 | |
|---|---|---|---|
| String | 不可变的 每次修改都会创建一个新对象 | ✅ | 字符串常量,字符串处理不需要修改时 |
| StringBuffer | 可变的 修改可在原对象上进行 | ✅ (同步) | 频繁修改且在多线程中访问,需保证线程安全 |
| StringBuilder | 可变的 | ❌ | 频繁修改且在单线程中访问,速度快 |
- String
- 只读字符串,String 不是基本数据类型,而是一个对象。
- 从底层源码来看,String 是一个 final 类型的字符数组,所引用的字符串不能被改变,一经定义,无法再增删改。
- 每次对 String 的操作都会生成一个新的 String 对象。
/* String 底层源码 */
private final char value[];
每次 + 操作:隐式地在堆上 new 了一个原字符串相同的 StringBuilder 对象,再调用 append 方法,拼接 + 后面的字符。
- StringBuffer
- 继承 AbstractStringBuilder 抽象类
- 底层是可变的字符数组
- 适合场景:频繁地字符串操作
- StringBuffer
对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。
- StringBuilder
- 继承 AbstractStringBuilder 抽象类
- 底层是可变的字符数组
- 适合场景:频繁地字符串操作
- StringBuilder 没有对方法加同步锁,所以是
非线程安全的。
/**
* AbstractStringBuilder.java 抽象类
* The value is used for character storage.
*/
char[] value;
总结
String是final修饰的,不可变,每次操作都会产生新的String对象。StringBuffer和StringBuilder都是在原对象上操作。StringBuffer是线程安全的,StringBuilder线程不安全。StringBuffer方法都是synchronized修饰的- 性能:
StringBuilder > StringBuffer > String - 场景:
- 经常需要改变字符串内容时,使用
StringBuffer和StringBuilder。 - 优先使用
StringBuilder,多线程使用共享变量时,使用StringBuffer。
- 经常需要改变字符串内容时,使用
StringBuffer、StringBuilder 区别、使用场景。
Java 集合分类
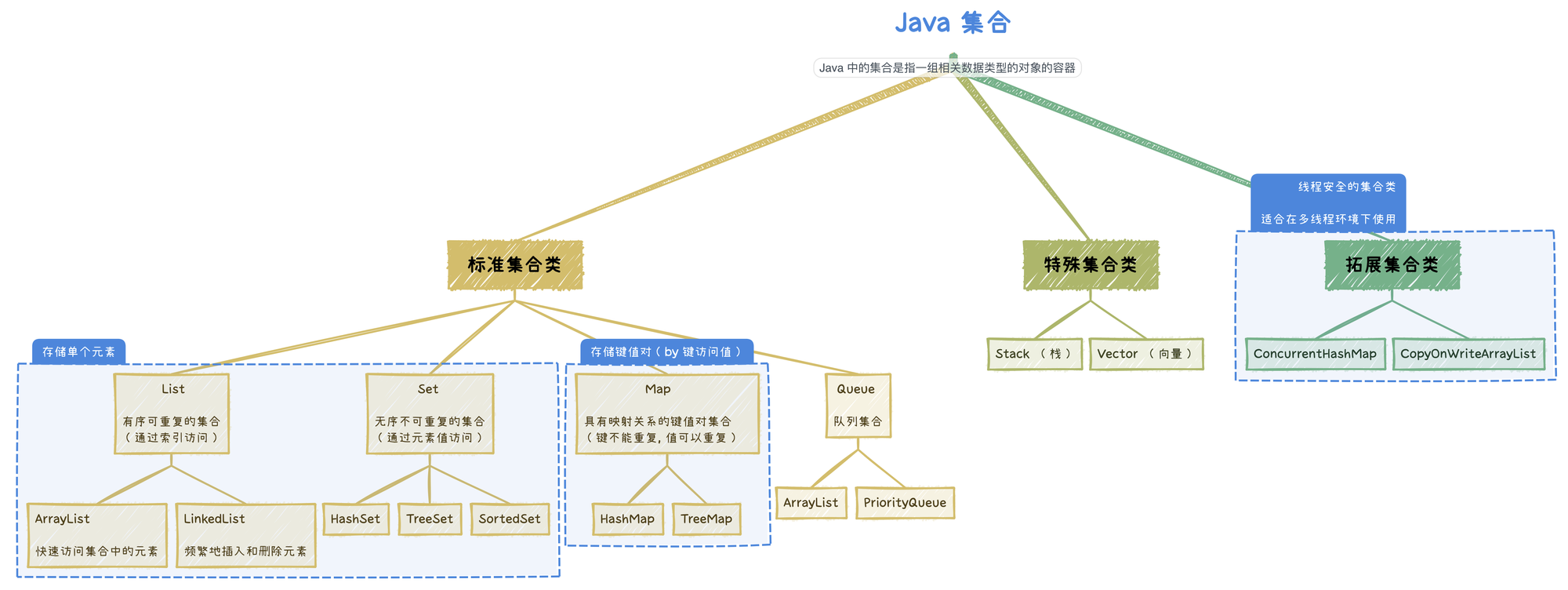
Java 中的集合是指一组相关数据类型的对象的容器。Java 提供了许多集合类,可以根据实际情况选择适合的集合类来使用。
常用的 Java 集合包括:
▪ List:有序可重复的集合,例如 ArrayList、LinkedList
▪ Set:无序不可重复的集合,例如 HashSet、TreeSet
▪ Map:具有映射关系的键值对集合,例如 HashMap、TreeMap
▪ Queue:队列集合,例如 LinkedList、PriorityQueue
另外还有一些特殊的集合类,例如 Stack(栈)、Vector(向量)
除了以上的标准集合类,Java 还提供了一些扩展集合类,例如 ConcurrentHashMap、CopyOnWriteArrayList 等,它们是线程安全的集合类,适合在多线程环境下使用。
在使用集合类时,需要根据实际需求选择适合的集合类,不同的集合类有不同的优劣点。
🆙 在使用集合类时,还需要注意集合类的 并发性、可扩展性、性能 等问题。
 分类
分类
List、Set
- List
- 有序,按对象进入的顺序保存对象
- 可重复,允许多个
null元素对象 - 可以使用
iterator取出所有元素,再逐一遍历,还可以使用get(int index)获取指定下标的元素
- Set
- 无序,不可重复,最多只有一个
null元素对象 - 取元素时,只能用
iterator接口取得所有元素,再逐一遍历
- 无序,不可重复,最多只有一个
ArrayList、LinkedList 区别
- Array(数组)
- Array 是基于索引(index)的数据结构。
- 它使用索引在数组中的搜索和读取数据是非常快的。
- 查找:时间复杂度
O(1) - 删除:开销很大,需重排数组中所有元素(前移)
- 缺点:数组初始化必须执行初始化的长度,否则报错
int[] a = new int[4]; // 推荐使用 int[] 方式初始化
int c[] = {1, 2, 3, 4}; // 长度:4,索引范围:[0,3]
- List(集合)
- 有序集合,元素可重复,提供了按索引访问的方式,继承 Collection 类。
- List 有两个重要的实现类:ArrayList、LinkedList。
- ArrayList
- 能够自动增长容量的数组
ArrayList.toArray()返回一个数组ArrayList.asList()返回一个列表- ArrayList 底层是 Array,数组扩容实现
- LinkedList
- 双链表
- LinkedList 在添加、删除元素时,比 ArrayList 性能高。【数据量很大、频繁操作时】
- LinkedList 在 get、set 元素,比 ArrayList 性能差。【数据量很大、频繁操作时】
总结
- ArrayList
- 基于
动态数组,连续内存存储,适合下标访问(随机访问) - 扩容机制:因为数组长度固定,超出长度存数据时,需要新建数组,然后将老数组的数据拷贝到新数组。
- 如果不是尾部插入数据元素还是涉及到元素的移动(往后复制一份,插入新元素)。
- 使用
尾插法并指定初始容量,可以极大提升性能、甚至超过 LinkedList(需要创建大量的 node 对象)。
- 基于
- LinkedList
- 基于
链表,可以存储在分散的内存中,适合做数据插入及删除操作,不适合查询(需要逐一遍历)。 - 遍历:必须使用
iterator,不能使用for循环。因为每次 for 循环体内通过get(i)取得某一元素时都需要对 list 重新进行遍历,性能消耗极大。 - 不要试图使用
indexOf等返回元素索引,并利用其进行遍历,使用 indexOf 对 list 进行遍历,当结果为空时会遍历整个 list。
- 基于
ArrayList 扩容机制
以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。
ArrayList 底层使用的是 Object 数组,在无参构造函数中默认初始化长度为 10,当需要扩容时会将原数组中的元素重新拷贝到长度为原数组的 1.5 倍的新数组中,扩容代价比较高;
Hash 冲突
HashCode 相同的场景【Hash 冲突】 面试题 1️⃣ 两个不相等的对象,可能有相同的 hashCode❓
答:有可能。在产生 Hash 冲突时。
处理 Hash 冲突的方式:
- 拉链法:每个 hash 表的节点都有一个 next 指针,多个 hash 表节点可以用 next 指针构成一个单向链表,被分配到同一个索引上的多个节点可以用该单向链表进行存储。
- 开放地址法:一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
- 再哈希法:又叫双哈希法,有多个不同的 hash 函数。当发生冲突时,使用第二个、第三个、…… 等哈希函数计算地址,直到无冲突。
HashMap 扩容机制

上图大概演示 JDK1.7、1.8 图
✅️ JDK 7
1. 生成新数组【原数组大小 2 倍】
2. 遍历老数组中的每个位置上的 链表上的每个元素
3. 取每个元素的 key,并基于新数组长度,计算出每个元素在新数组中的下标
4. 将元素添加到新数组中
5. 所有元素转移完了之后,将新数组赋值给 HashMap 对象的 table 属性
✅️ JDK 8
1. 生成新数组【原数组大小 2 倍】
2. 遍历老数组中的每个位置上的 链表/红黑树
3. If is 链表,则直接将链表中的每个元素重新计算下标,并添加到新数组中
4. If is 红黑树,则先遍历红黑树,先计算出红黑树中每个元素对应在新数组中的下标位置
① 统计每个下标位置的元素个数
② If 该位置下的元素个数超过 8,则生成一个新的红黑树,并将根节点添加到新数组的对应位置
③ If 该位置下的元素个数不超过 8,则生成一个链表,并将链表的头节点添加到新数组的对应位置
5. 所有元素转移完了之后,将新数组赋值给 HashMap 对象的 table 属性
📢 转移 红黑树,新树中红黑树结构可能会变(树的结构,会根据数组大小重新计算)
HashMap 底层变化(JDK1.7 → jdk1.8)
HashMap 中 put()
HashMap、HashTable 区别,及其底层实现【Older 了】
(1)两者父类不同
- HashMap 继承自 AbstractMap 类。
- HashTable 继承自 Dictionary 类。
- 🪣 两者都实现了 Map、Cloneable(可复制)、Serializable(可序列化)三个接口。
(2)对外提供的接口不同
- HashTable 比 HashMap 多提供了
elements()和contains()两个方法。 elements()- 该方法继承自 HashTable 的父类 Dictionary。
- 用于返回此 HashTable 中的 value 的枚举。
contains()- 作用:判断该 HashTable 是否包含传入的 value。同
containsValue()一致。 - 事实上,containsValue() 只是调用了一下 contains() 方法。
- 作用:判断该 HashTable 是否包含传入的 value。同
(3)对 null 的支持不同
- HashTable
key 和 value 都不可为 null。
- HashMap
- key 可以为 null,但只有一个,因为 key 必须保证唯一性;【
key 只有一个 null】 - 可以有多个 key 对应的 value 为 null。【
value 可有多个 null】
- key 可以为 null,但只有一个,因为 key 必须保证唯一性;【
(4)安全性不同
HashMap
线程不安全- 在多线程并发环境下,可能会产生
死锁等问题,因此需要开发人员自己处理多线程的安全问题。
HashTable
线程安全- HashTable 每个方法上都有
synchronized关键字,因为可直接用于多线程中。
💡虽然 HashMap 线程不安全,但它的效率远远高于 HashTable,因为大部分的使用场景是
单线程。❗️ 当需要多线程操作时,可以使用
线程安全的ConcurrentHashMap。ConcurrentHashMap- 线程安全
- 效率比 HashTable 高好多倍。
- 因为 ConcurrentHashMap 使用了
分段锁,并不对整个数据进行锁定。
(5)初始容量大小和每次扩容量大小不同
(6)计算 hash 值的方法不同
总结
- HashMap
- HashMap 方法没有
sychronized修饰,线程不安全 - 允许
key和value为null - 底层实现:数组+链表
- JDK8 开始链表高度为 8、数组长度超过 64,链表转变为
红黑树,元素以内部类 Node 节点存在 - 计算 key 的 hash 值,二次 hash 然后对数组长度取模,对应到数组下标。
- 如果没有产生 hash 冲突(下标位置没有元素),则直接创建 node 存入数组;
- 如果产生 hash 冲突,先进行 equals 比较。相同,则取代该元素;不同,则判断链表高度插入链表,链表高度达到 8,并且数组长度到 64 则转变为红黑树,长度低于 64 则将红黑树转回链表。
- key 为 null 时,存储在下标 0 的位置。
- JDK8 开始链表高度为 8、数组长度超过 64,链表转变为
- 数组扩容:
- HashMap 方法没有
- HashTable
- 线程安全
- 不允许
key和value为null - 底层实现:
- 数组扩容:
ConcurrentHashMap 原理,JDK7 和 JDK8 区别。
✅️ JDK 7
🎯 数据结构:
- ReentrantLock + Segment + HashEntry。
- 一个 Segment 中包含一个 HashEntry 数组,每个 HashEntry 又是一个链表结构。
🎯 元素查询:
- 二次 hash。第一次 hash 定位到 Segment,第二次 hash 定位到元素所在链表的头部。
🎯 锁:Segment 分段锁。
- Segment 继承了 ReentrantLock,锁定操作的 Segment,其他的 Segment 不受影响
- 并发度为 Segment 个数,可以通过构造函数指定
- 数组扩容不会影响其他的 Segment。
- 锁粒度小
🎯 get() 无需加锁,volatile 保证可见性
✅️ JDK 8
🎯 数据结构:
- synchronized + CAS + Node + 红黑树。
- Node 的 val 和 next 都用 volatile 修饰,保证可见性。
- 查找、替换、赋值操作都使用 CAS。
🎯 锁:锁链表的 head 节点,不影响其他元素的读写,锁粒度更细,效率更高,扩容时,阻塞所有的读写操作、并发扩容。
🎯 读操作无锁:
- Node 中 val 和 next 使用 volatile 修饰,读写线程对该变量互相可见。
- 数组用 volatile 修饰,保证扩容时被读线程感知。
📢 Sychronized 在 JDK 8 中做了优化,锁粒度不如之前重了。
CAS 是乐观锁机制,比之 Sychronized、ReentrantLock 效率更高。
ConcurrentHashMap 扩容机制

✅️ JDK 7
1. ConcurrentHashMap 基于 Segment 分段锁实现
2. 每个 Segment 相对于一个小型的 HashMap
3. 每个 Segment 内部会进行扩容,和 HashMap 的扩容逻辑类似
4. 先生成新的数组,然后转移元素到新数组中
5. 扩容的判断:每个 Segment 内部单独判断,判断是否超过阈值
✅️ JDK 8
1. ConcurrentHashMap 不再基于 Segment 分段锁实现
2. 当某个线程进行 put 时,如果发现 ConcurrentHashMap 正在进行扩容,则该线程一起进行扩容
3. 若发现没有正在进行扩容,则将 key-value 添加到 ConcurrentHashMap 中,然后判断是否超过阈值,超过则进行扩容
4. ConcurrentHashMap 支持多个线程同时扩容
5. 扩容之前,先生成一个新的数组
6. 在转移元素时,先将原数组分组,将每组分给不同的线程来进行元素的转移,每个线程负责一组或多组的元素转移工作
ConcurrentHashMap 如何保证线程安全,JDK8 有什么变化?
JDK8 中 ConcurrentHashMap 为什么放弃了分段锁?
ConcurrentHashMap 与 HashMap 底层区别
CurrentHashMap 在 HashMap 基础上增加了分段式锁。
扩展
🔻底层数据结构(JDK1.8 之后)
HashMap → 在解决哈希冲突时,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间。
CurrentHashMap → 数组+链表/红黑二叉树
🔻是否线程安全
HashMap → 非线程安全
CurrentHashMap → 线程安全
Hashtable → 线程安全 → 因为 Hashtable 内部的方法基本都经过 synchronized 修饰 Hashtable 基本被淘汰
🔻是否线程安全
HashMap → 可以存储 null 的 key 和 value,但 null 作为键只能有一个,作为值可以有多个
CurrentHashMap →
CopyOnWriteArrayList 底层原理
Stream 流(Java 8 新特性)
Java 8 中的 Stream 流除了 map 方法外,还有很多其他方法,这里列举一些常用的:
✅ filter(Predicate<T> predicate):对流中的元素进行过滤,只保留满足条件的元素。
✅ distinct():去除流中的重复元素。
✅ sorted():对流中的元素进行排序,默认为自然排序,也可以传入自定义的 Comparator。
✅ peek(Consumer<T> action):对流中的元素进行遍历,同时执行指定的操作。
✅ limit(long maxSize):限制流中元素的数量,只保留前 maxSize 个元素。
✅ skip(long n):跳过流中的前 n 个元素,只保留剩余的元素。
✅ reduce(BinaryOperator<T> accumulator):将流中的元素按照指定方式进行归约,返回归约的结果。
✅ collect(Collector<T, A, R> collector):将流中的元素进行收集,返回指定类型的结果。
这些方法可以组合使用,构成复杂的数据处理操作,实现代码的简洁、高效。
Java 中异常体系
Throwable:顶级父类。下有两个子类:Exception、Error。Exception:不会导致程序停止。RuntimeException:运行时异常。发生在程序运行过程中,会导致程序当前线程执行失败。CheckedException:检查时异常。发生在程序编译过程从,会导致程序编译不通过。
Error:程序无法处理的错误,一旦出现这个错误,程序将被迫停止运行。
接口、抽象类
- 抽象类可以存在普通成员函数,而接口中只能存在
public abstract方法。 - 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是
public static final类型的。 - 抽象类只能继承一个,接口可以实现多个。
设计目的
- 接口:对类的行为进行 “约束”。
- 更准确的说是一种 “有” 约束,因为接口不能规定类不可以有什么行为。
- 也就是提供一种机制,可以强制要求不同的类具有相同的行为。
- 它只约束了行为的有无,但不对如何实现行为进行限制。
- 抽象类:代码复用。
- 当不同的类具有某些相同的行为(记为行为集合 A),且其中一部分行为的实现方式一致时(A 的非真子集,记为 B),可以让这些类都派生于一个抽象类。 在这个抽象类中实现了 B,避免让所有的子类来实现 B,这就达到了代码复用的目的。
- 而
A - B的部分,留给各个子类自己实现。 - 正是因为
A-B在这里没有实现,所以抽象类不允许实例化出来。(否则当调用到 A-B 时,无法执行)
英文助记
- 抽象类:对类本质的抽象。
- 表达的是
is a的关系,比如:BMW is Car。 - 抽象类包含并实现了子类的通用特性,将子类存在差异化的特性进行抽象,交由子类去实现。
- 表达的是
- 接口:对行为的抽象。
- 表达是的
like a的关系。比如:Bird like a Aircraft。(像飞行器一样可以飞),但其本质上is a Bird。 - 接口的核心是定义行为,即实现类可以做什么,至于实现类主体是谁、是如何实现的,接口并不关心。
- 表达是的
使用场景
- 抽象类:关注一个事物的本质时,用抽象类;
- 接口:关注一个操作时,用接口。
区别
- 抽象类的功能要
远超于接口,但是抽象类的代价高。 - 因为从高级语言来说(从实际设计上来说),每个类只能继承一个类。在这个类中,你必须继承或编写出其所有子类的所有共性。
- 虽然接口在功能上会弱化许多,但是它只是针对一个动作的描述。而且你可以在一个类中同时实现多个接口。在设计阶段会降低难度。
泛型中,extends、super 区别
深拷贝、浅拷贝
- 深拷贝
- 被复制对象的所有变量都含有与原来的对象相同的值。而那些引用其他对象的变量将指向被复制过的新对象,而不再是原有的那些被引用的对象。
- 换言之,深拷贝把要复制的对象所引用的对象都复制了一遍。
- 浅拷贝
- 被复制对象的所有变量都含有与原来的对象相同的值。而所有的对其他对象的引用仍然指向原对象。
- 换言之,浅拷贝仅仅复制了该对象,并没有复制它索引用的对象。
面向对象
重载、重写
Java 创建对象的 4 种方式
- new 创建新对象
- 通过反射机制
- 采用 clone 机制
- 通过序列化机制
Java 是值传递 or 引用传递?
Java和 C++ 不同,C++ 中有引用传递的函数调用方式,而 Java 中只有值传递。
扩展
🔻值传递:指的是在方法调用时,传递的参数是按值的拷贝传递,传递的是值的拷贝,也就是说传递后就互不相关了。
🔻引用传递:指的是在方法调用时,传递的参数是按引用进行传递,其实传递的引用的地址,也就是变量所对应的内存空间的地址。传递的是值的引用,也就是说 传递前和传递后都指向同一个引用(也就是同一个内存空间)
【注】如果不深究的话,还会一直停留在基本数据类型为值传递,对象类型为引用传递的错误理解中。
动态代理
1️⃣ JDK 动态代理
2️⃣ cglib 动态代理
区别:
【答案1】
JDK 代理有实现接口的类,通过反射实现;cglib 用的是继承,子类拦截父类加上自己的逻辑。
【答案2】
JDK 动态代理只提供接口的代理,不支持类的代理。
CGLIB 通过继承的方式,如果某个类被标记为final,则它无法使用CGLIB做动态代理。
Java 新特性
✅ Java 8(2014年):
▪ Lambda 表达式:简化函数式编程。
▪ Stream API:用于处理集合,支持函数式操作,如过滤、映射和聚合。
▪ 默认方法:在接口中提供默认实现,提高接口的灵活性。
▪ Optional 类:减少空指针异常,提高代码可读性。
▪ 时间 API:提供了一组强大的时间操作类,简化了日期和时间的操作。
▪ 重复注解:允许在同一个地方多次声明同一个注解,提高了代码的可读性。
▪ CompletableFuture 类:简化异步编程,提供更好的错误处理和异常处理机制。
▪ 方法引用:允许直接引用现有方法或构造函数,避免了重复编写类似的代码。
▪ Nashorn 引擎:提供了一种基于 JavaScript 的解决方案,允许将 JavaScript 代码嵌入到 Java 应用程序中。
✅ Java 9(2017年):
▪ 模块系统(Project Jigsaw):将 Java 的庞大代码库划分为可重用的模块,简化大型应用的构建和维护。
▪ 改进的 JShell 工具:Java 的交互式命令行工具,用于快速尝试和测试 Java 代码片段。
▪ 新的集合工厂方法:方便地创建不可变集合,如 List.of()、Set.of() 和 Map.of()。
▪ 改进的 Stream API:提供了更多的流操作方法,使流操作更加强大和灵活
▪ Reactive Streams:提供了一种标准化的异步流处理框架
▪ 改进的 Optional 类:提供了更多的 API 方法和更好的 null 值处理机制
▪ HTTP 2 客户端:支持 HTTP/2 协议的客户端 API
✅ Java 10(2018年):
▪ 局部变量类型推断:使用 var 关键字自动推断局部变量的类型,简化代码。
▪ 线程局部变量回收:提供了一种新的垃圾回收器,可用于回收线程局部变量。
▪ 应用类数据共享:允许多个 Java 应用程序共享类数据。
▪ G1 垃圾回收器改进:提高了垃圾回收的效率和稳定性。
▪ 垃圾收集器接口改进:提高了垃圾收集器的可插拔性和灵活性。
▪ 基于时间的版本控制系统:允许使用时间作为版本号来管理代码版本。
▪ 针对低内存设备的堆分配器:为低内存设备提供更好的内存管理机制。
✅ Java 11(2018年,长期支持版本):
▪ 新的 HTTP 客户端 API:支持 HTTP/2 和 WebSocket,提供了更现代化的编程方式。
▪ 改进的垃圾收集:引入了 ZGC 和 Epsilon 垃圾收集器。
▪ String 类的新方法:如 lines()、isBlank()、strip() 等。
✅ Java 12 - 17 的部分新特性:
▪ Switch 表达式:简化 switch 语句的编写,支持使用箭头语法。
▪ 文本块:简化多行字符串字面量的表示。
▪ Records:简化数据类的定义,自动为其生成构造函数、getter、hashCode()、equals() 和 toString() 方法。
▪ Pattern Matching for instanceof(预览功能):简化 instanceof 操作符的使用,避免显式类型转换。
▪ 密封类
▪ 删除实验性 AOT 和 JIT 编译器
▪ 特定于上下文的反序列化过滤器
Java 未来的发展趋势将是更加注重性能、安全和可靠性。以下是一些可能会影响 Java 未来发展的趋势:
▪ 云计算和容器化:Java 非常适合在云环境中使用,因为它具有高度的可移植性和跨平台性。Java 的未来将会更加注重云计算和容器化的支持。
▪ 数据科学和人工智能:Java 正在逐渐成为数据科学和人工智能领域的重要语言之一,未来 Java 可能会提供更多的支持和功能。
▪ 静态类型检查:静态类型检查是提高代码质量和可靠性的重要手段,Java 未来可能会提供更加严格和强大的类型检查机制。
▪ 简化语法:比如 Java 16 中的 Records 和 Sealed Classes 是一种更简洁的语法,未来 Java 可能会继续简化语法以提高代码的可读性和可维护性。
总之,Java 未来将继续发展和改进,以适应不断变化的编程环境和需求。
✅ 只需关注 LTS(长期支持版本)的 Java 8、11、17 即可