JVM
Siona
JVM
Java 类加载器
JDK 自带 3 个类加载器:
BootStrapClassLoader
BootStrapClassLoader 是 ExtClassLoader 的父类加载器,默认负责加载 %JAVA_HOME%/lib 下的 jar 包和 class 文件。
ExtClassLoader
ExtClassLoader 是 AppClassLoader 的父类加载器,负责加载 %JAVA_HOME%/lib/ext 文件夹下的 jar 包和 class 文件。
AppClassLoader
AppClassLoader 是自定义加载器的父类,负责加载 classpath 下的类。其称为系统类加载器、线程上下文加载器。
自定义加载器
继承 ClassLoader 实现自定义类加载器。
类加载器双亲委派模型
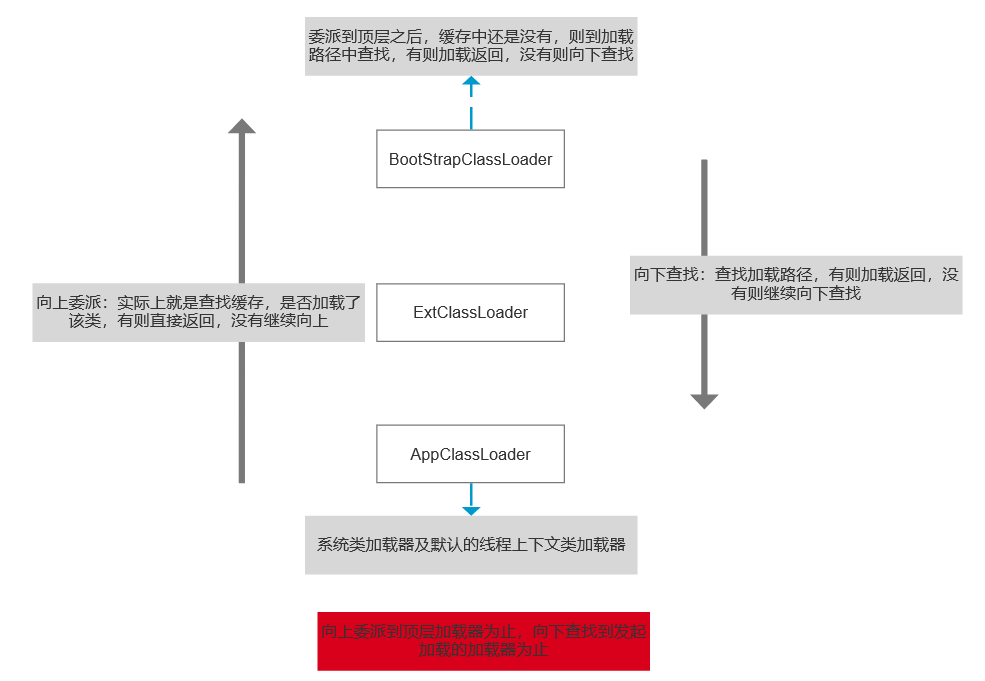
好处
- 安全性:避免用户自己编写的类动态替换 Java 的一些核心类,比如 String。
- 避免了类的重复加载,因为 JVM 中区分不同类,不仅仅是根据类名,相同的 class 文件被不同的 ClassLoader 加载就是不同的两个类。
双亲委派机制的缺陷
类加载的双亲委派机制有个缺陷,就是顶层 ClassLoader 无法访问底层 ClassLoader 加载的类。
如 Java 核心类库的Driver接口使用 BootstrapClassLoader,但是各个厂商的实现类很显然是下层的类加载器加载的。
解决这个问题的方式就是 SPI 机制(实现类的配置化),使用 ServiceLocator 加载数据库驱动,本质是用的Thread类中的 ContextClassLoader。
JVM 内存模型
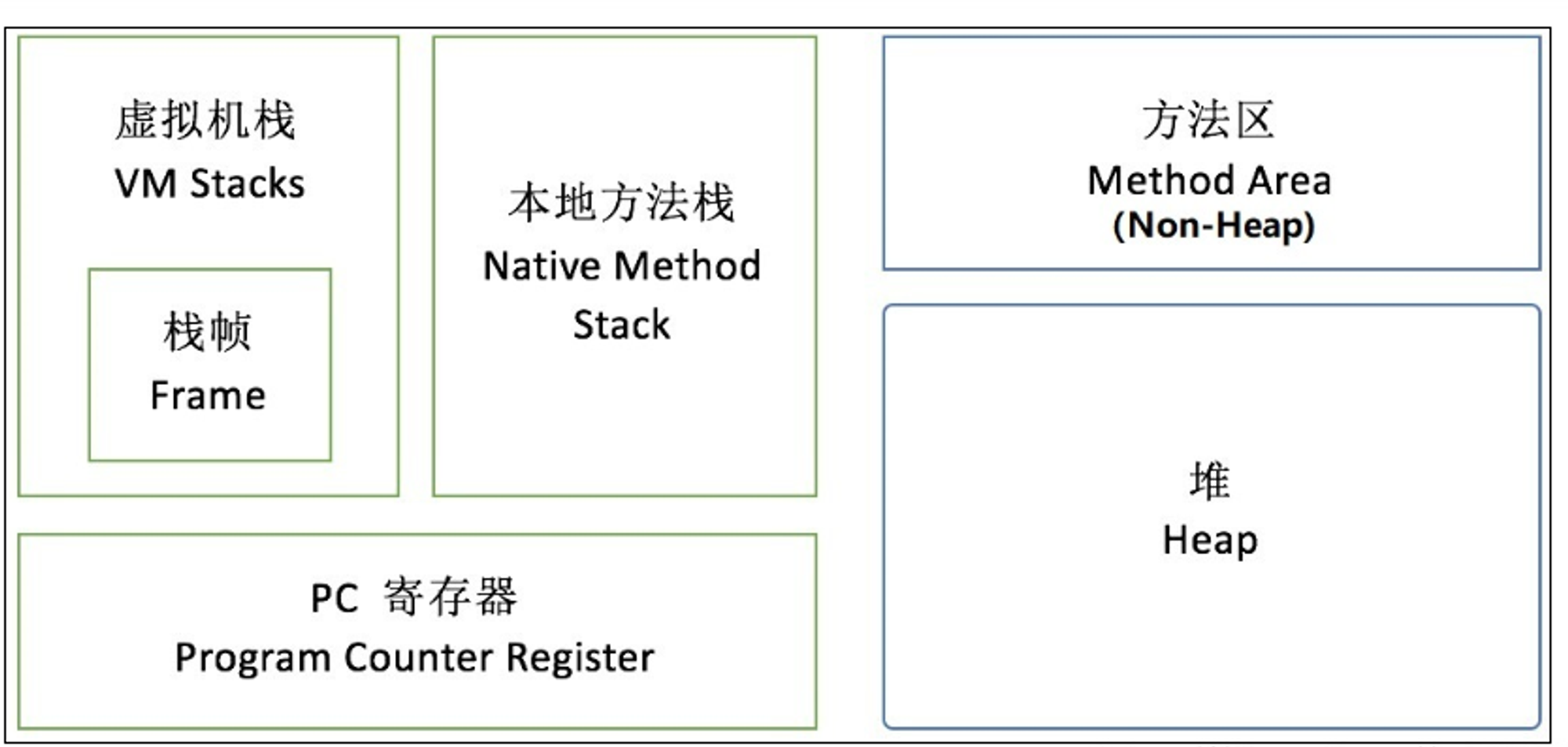
JVM 内存模型分为以下几个区域:
✅ 程序计数器(Program Counter Register):每个线程都有自己的程序计数器,用于指示当前线程执行的字节码指令的行号,以便线程执行时能够回到正确的位置。
✅ 虚拟机栈(JVM Stack):也称为 Java 方法栈,用于存储方法执行时的局部变量表、操作数栈、动态链接、方法出口等信息。每个线程在执行一个方法时,都会为该方法分配一个栈帧,并将该栈帧压入虚拟机栈,当方法执行完毕后,虚拟机会将其出栈。
✅ 本地方法栈(Native Method Stack):与虚拟机栈类似,用于存储本地方法的执行信息。
✅ 堆(Heap):用于存储对象实例,是 JVM 中最大的一块内存区域。堆是被所有线程共享的,当创建一个新对象时,对象实例存储在堆中,堆中存储的对象实例都有一个标记用于标记对象是否存活。垃圾回收器会周期性地回收那些没有被标记为存活的对象。
✅ 方法区(Method Area):用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。方法区也是被所有线程共享的。
✅ 运行时常量池(Runtime Constant Pool):是方法区的一部分,用于存储编译期间生成的各种字面量和符号引用,这些内容在类加载后进入常量池中。
其中,程序计数器、虚拟机栈、本地方法栈是线程私有的,堆、方法区、运行时常量池是线程共享的。
JVM 线程共享区
Java 的内存结构,堆分为哪几部分?默认年龄多大进入老年代?
JVM 垃圾回收器
JVM 垃圾回收算法
常见的垃圾回收算法有以下几种类型:
✅ 标记-清除算法(Mark-Sweep):分为标记和清除两个阶段。标记阶段遍历所有活动对象并打上标记,清除阶段将未被标记的对象删除。优点是不需要连续内存空间,缺点是清除后可能会产生内存碎片。
✅ 复制算法(Copying):将可用内存分为两块,只使用其中一块,当这一块满了后,将存活对象复制到另一块未被使用的空间,然后清除使用的那块。优点是简单高效,没有内存碎片问题,缺点是需要额外的空间来存储复制后的对象。
✅ 标记-整理算法(Mark-Compact):在标记阶段与标记-清除算法类似,但在清除阶段将存活对象整理到内存的一端,然后清除边界以外的所有对象。优点是不会产生内存碎片,缺点是比较慢。
✅ 分代收集算法(Generational):根据对象存活的时间将内存分为几个区域,每个区域采用不同的回收策略。一般将新生代分为 Eden 区和两个 Survivor 区,采用复制算法回收;将老年代采用标记-清除或标记-整理算法回收。优点是提高了回收效率,缺点是需要额外的维护成本。
这些算法各有优缺点,适用于不同的场景。标记-清除算法简单,但可能会产生内存碎片;复制算法适用于短时间内产生大量垃圾的场景,但需要额外的空间存储复制后的对象;标记-整理算法不会产生内存碎片,但比较慢;分代收集算法提高了回收效率,但需要额外的维护成本。
对于一个应用程序,选择适合的垃圾回收算法需要综合考虑应用场景、内存需求、性能要求等多个因素,以便达到最佳的效果。
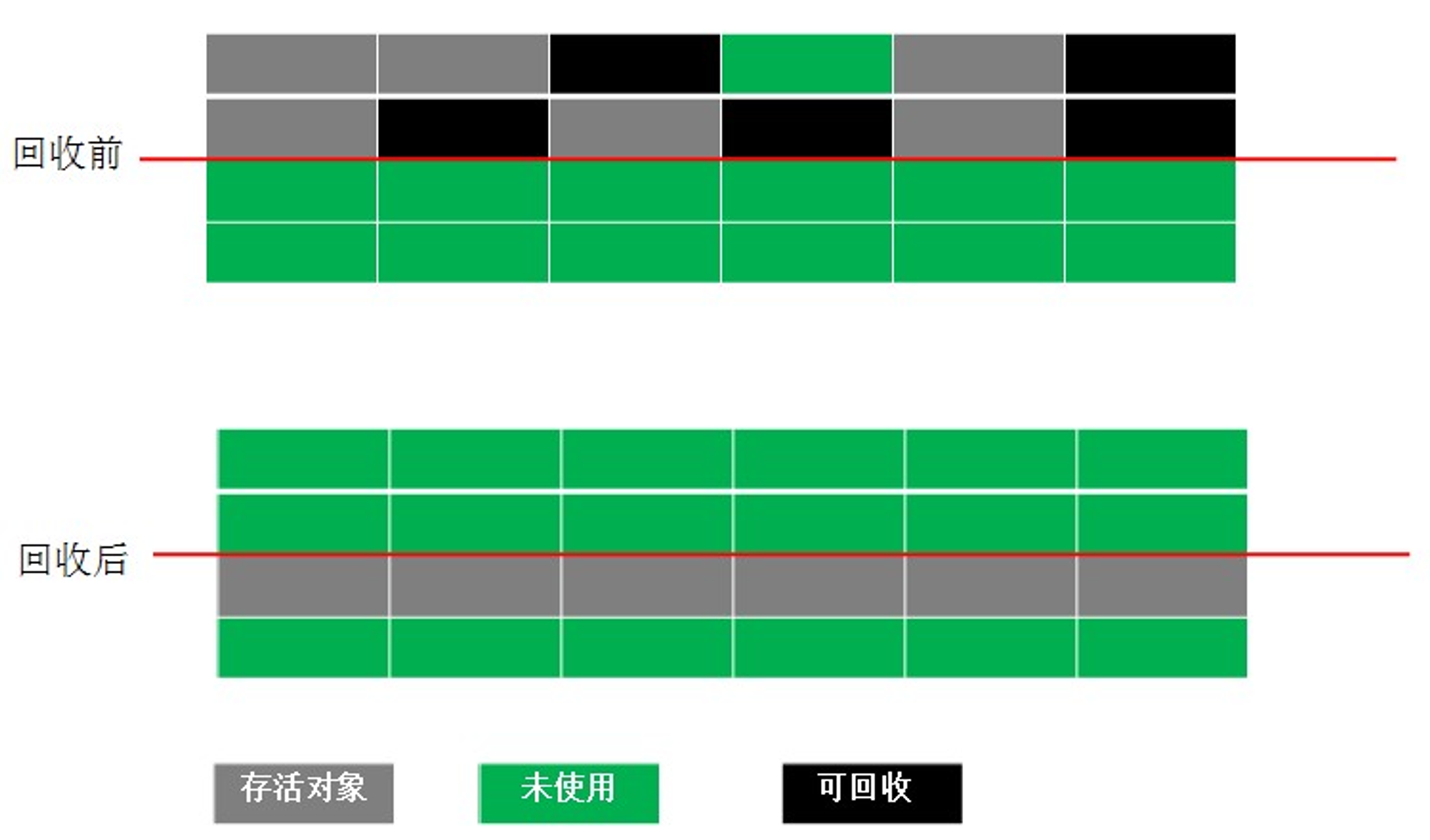
✅ Mark-Sweep(标记-清除)算法
标记-清除算法分为两个阶段:标记阶段和清除阶段。
标记阶段的任务是首先通过可达性分析,标记出所有需要回收的对象,
清除阶段就是回收被标记的对象所占用的空间。
优点:速度较快;
缺点:内存不连续,会造成内存碎片,碎片太多可能会导致后续过程中需要为大对象分配空间时无法找到足够的空间而提前触发新的一次垃圾收集动作。
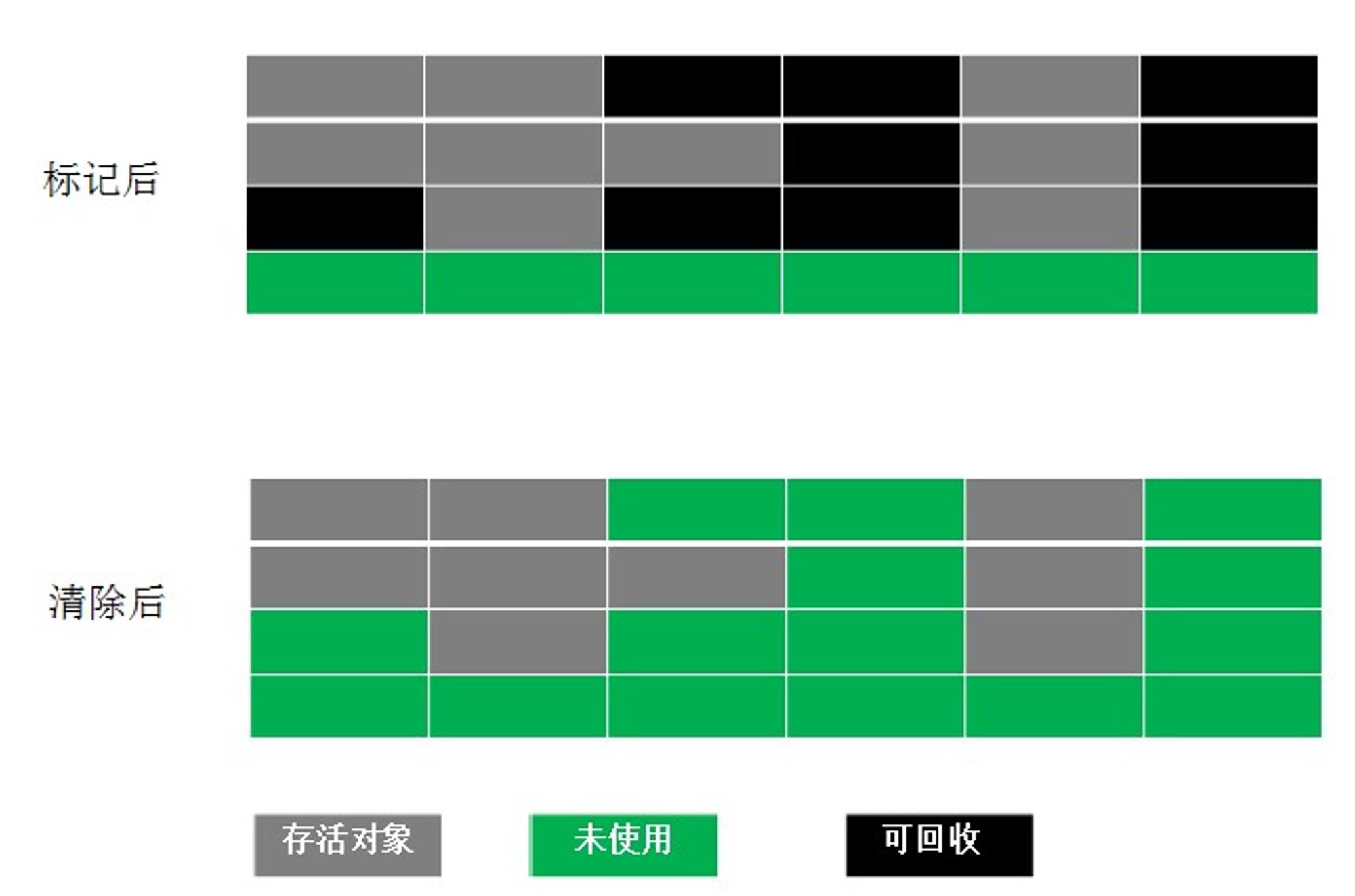
✅ Coping(复制)算法
为了解决Mark-Sweep算法的缺陷,他将可用内存按照容量划分为大小相等的两块,每次只使用一块。当这一块的内存用完了,就将还存活的对象复制到另一块上面,然后再把已使用的内存空间一次清理掉,这样一来就不容易出现内存碎片的问题。
这种算法虽然实现简单,运行高效且不容易产生内存碎片,但是却对内存空间的使用做出了高昂的代价,因为能够使用的内存缩减到原来的一半。很显然,Copying算法的效率跟存活对象的数目多少有很大的关系,如果存活对象很多,那么Copying算法的效率将会大大降低。
✅ Mark-Compact(标记-整理)算法(压缩算法)
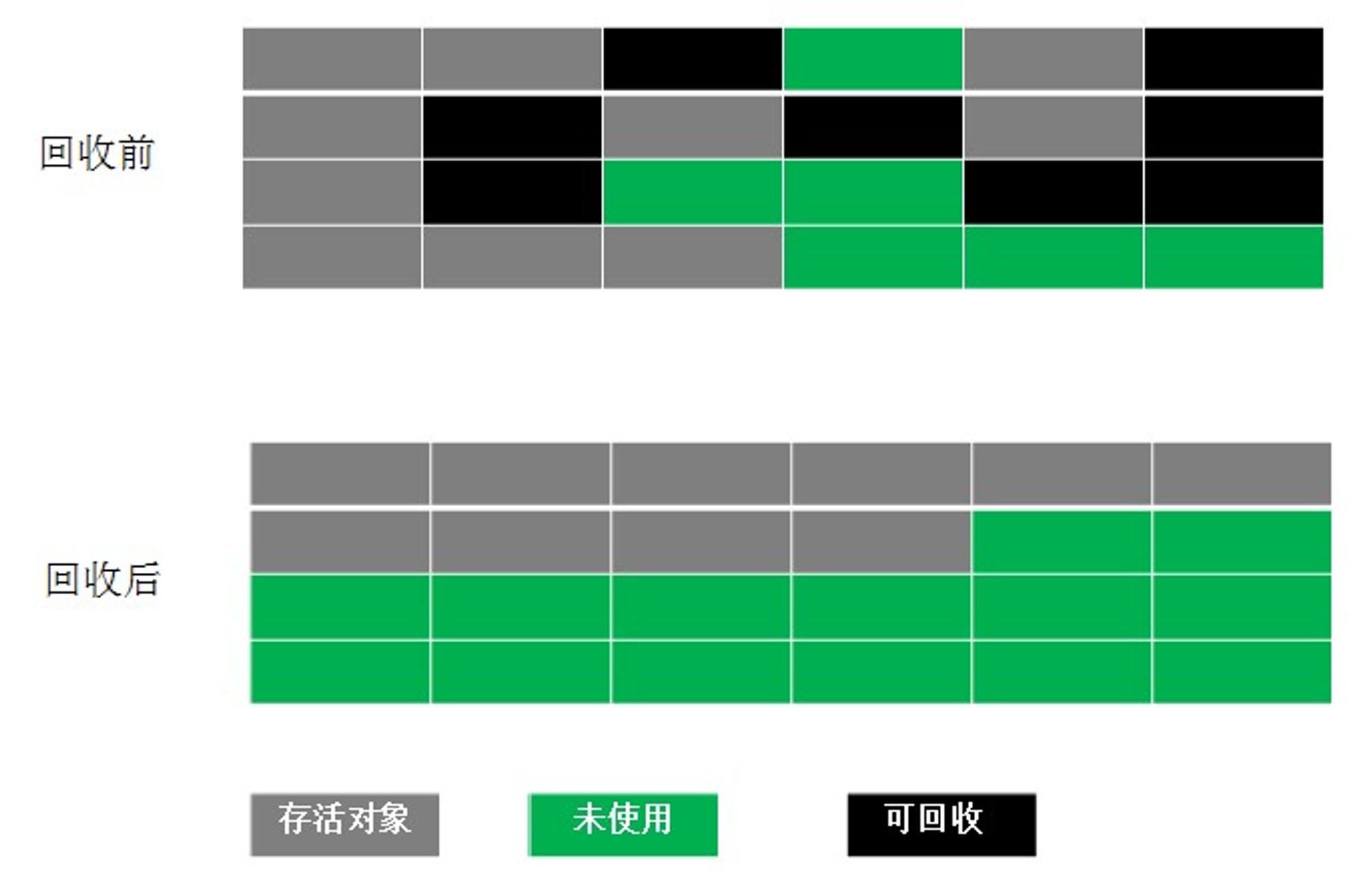
为了解决Copying算法的缺陷,充分利用内存空间,提出了Mark-Compact算法。
该算法标记阶段和Mark-Sweep一样,但是在完成标记之后,他不是直接清理可回收对象,而是将存活对象都向一端移动,然后清理掉端边界以外的内存
✅ Generation Collection(分代收集)算法
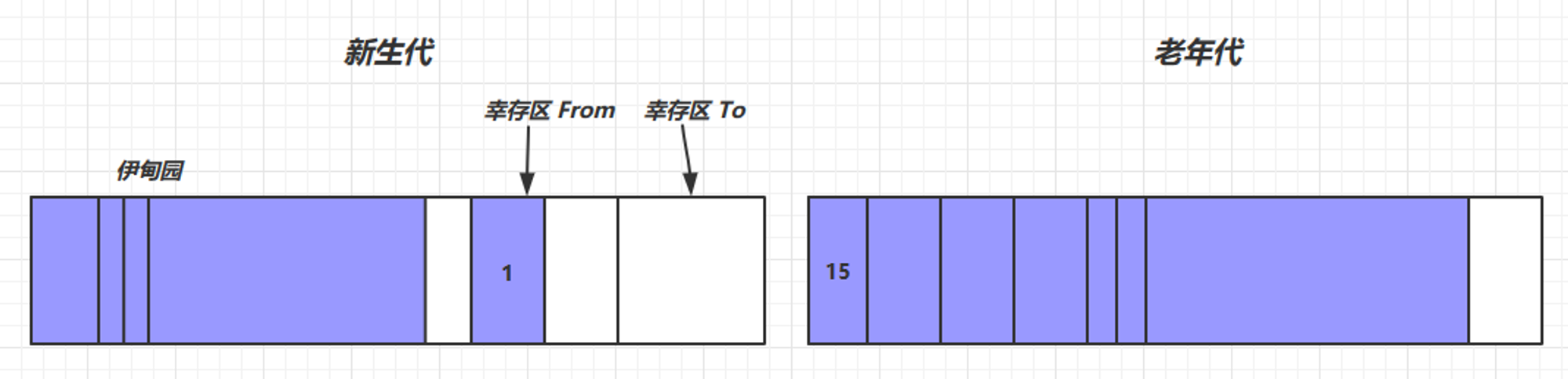
分代收集算法是目前大部分JVM的垃圾回收器采用的算法。他的核心思想是根据对象存活的生命周期将内存划分为若干个不同的区域。一般情况下将堆区划分为老年代(Tenured Generation)和新生代(Young Generation),老年代的特点是每次垃圾回收时,只有少数对象需要被回收,而新生代的特点是每次垃圾回收时都有大量的对象需要被回收
目前大部分垃圾回收器对于新生代都采取复制算法,因为新生代中每次垃圾回收都要回收大部分对象,也就是说需要复制的操作次数较少,但实际上不是按照1:1的比例来划分新生代的空间,一般来说是将新生代划分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden空间和其中的一块Survivor空间。当新生代的Eden Space和From Space空间不足时就会发生一次GC,进行GC后,Eden Space和From Space区的存活对象会被挪到To Space,然后将Eden Space和From Space进行清理。如果To Space无法足够存储某个对象,则将这个对象存储到老生代。在进行GC后,使用的便是Eden Space和To Space了,如此反复循环。当对象在Survivor区躲过一次GC后,其年龄就会+1。默认情况下年龄到达15的对象会被移到老年代中。
而由于老年代的特点是每次回收都只回收少量对象,一般使用的是标记-整理算法(压缩法),当老年代空间不足,会先尝试触发 minor gc,如果之后空间仍不足,那么触发 full gc,STW的时间更长
GC 如何判断对象可以被回收?
JVM 中哪些可以作为 gc root ?
项目中如何排查 JVM 问题?
对象在 JVM 中经历的过程
如何进行 JVM 调优?
字节码?作用?
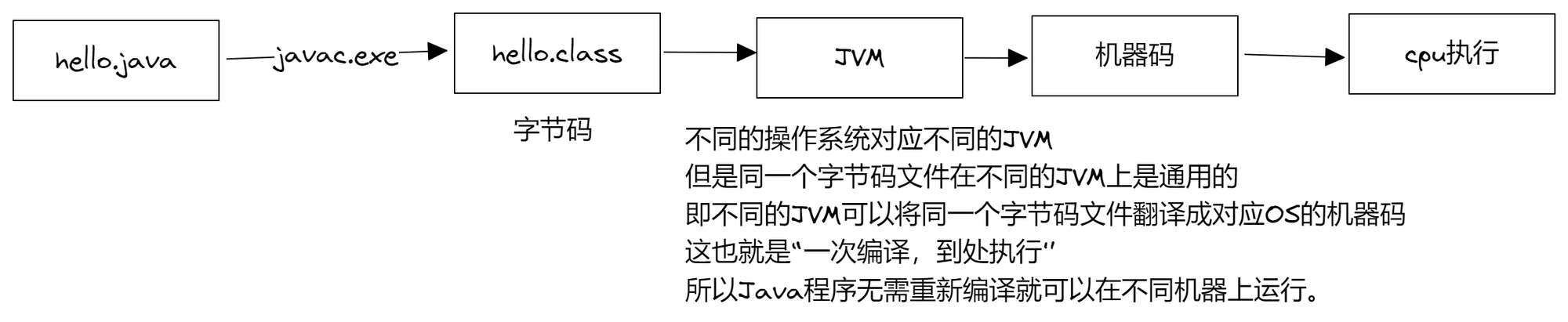
java 程序在编译后,得到的 .class 文件,我们称为字节码文件。
字节码是面向虚拟机(JVM)的,不针对某一种机器,这也是保证了 java 程序的可移植性的关键。